


Sur certains téléphones Samsung, des paramètres réseau restent verrouillés malgré les réinitialisations ou les mises à jour. Les restrictions liées à la carte SIM,…

Reacher Saison 3 : date de sortie, acteurs et intrigue
La troisième saison de 'Reacher', la série à succès adaptée des romans…

Les dimensions idéales pour un dépliant à 3 volets
Les dépliants sont l'un des supports marketing les plus utilisés, mais aussi…

Profiter d’un classement pour s’informer sur l’importance de la température d’un GPU
Le GPU est aussi connu par l’appellation de processeur graphique sur un…



Pourquoi 192.168.1..85 s’affiche sans page web ? Les causes fréquentes
Saisir 192.168.1.85 dans un navigateur et obtenir un écran vide : voilà…



Vues YouTube : prix de 1000 vues, meilleures astuces et stratégies !
Un CPM (coût pour mille vues) évolue entre 0,20 et 5 euros,…
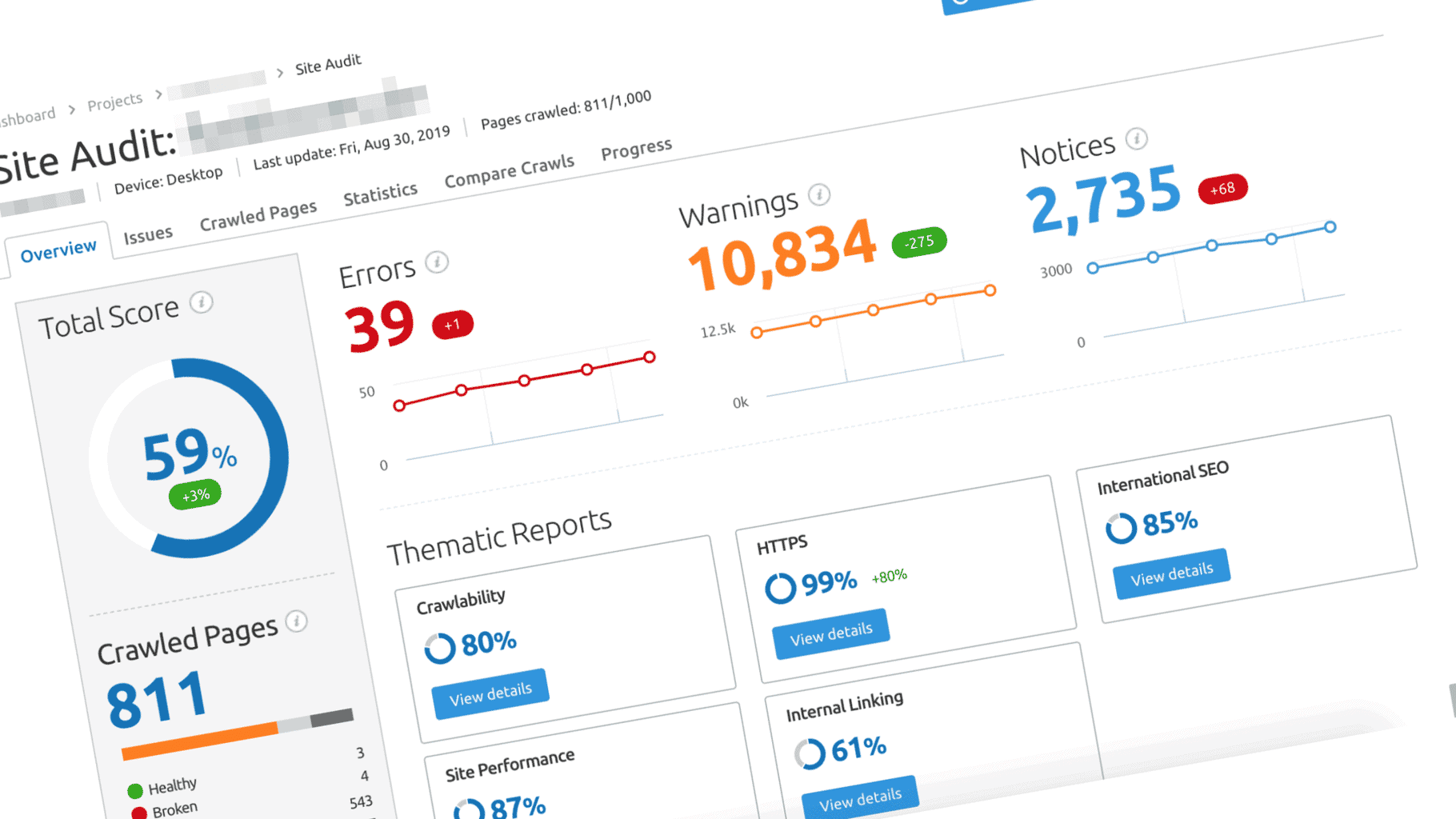
L’impact réel des métadonnées sur le classement d’un site web
Pousser un site web dans les tréfonds ou le hisser au sommet…

La chaîne de valeur d’Apple expliquée simplement et concrètement
Michael Porter a bouleversé les habitudes en classant la stratégie d'entreprise en…
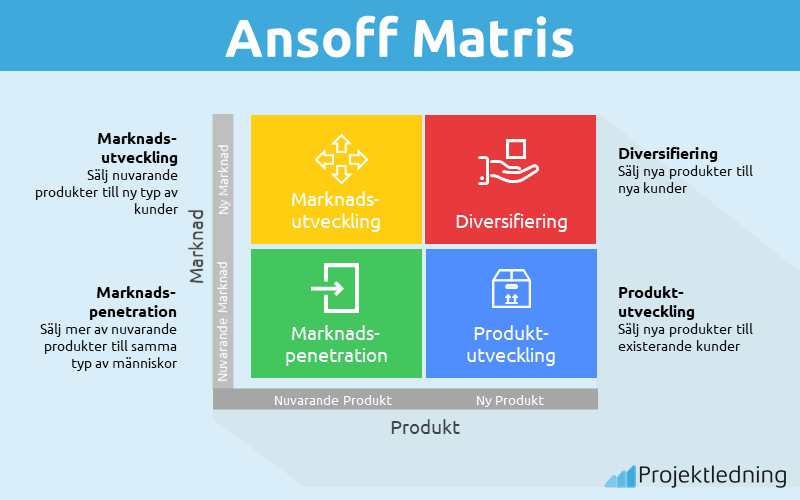
Créer une matrice Ansoff en quelques étapes simples et efficaces
Quatre cases, une promesse : celle de choisir sa trajectoire de croissance…


168.0..150 : comment changer le mot de passe Wi-Fi pas à pas
Un code Wi-Fi laissé intact depuis la première mise en service, c'est…










Pourquoi eservice ESIGELEC est devenu l’outil central de la vie étudiante ?
Une erreur de saisie, et soudain tout bascule : l'accès numérique à…

Samsung non enregistré sur le réseau : réglages cachés à vérifier en priorité
Sur certains téléphones Samsung, des paramètres réseau restent verrouillés malgré les réinitialisations…

Envie de passer à un iPhone 14 Pro Reconditionné pas cher sans risque ?
Le marché du smartphone reconditionné a vu ses ventes doubler en trois…
Exploration des outils gratuits d’IA pour améliorer votre productivité
À l’ère du numérique, optimiser sa productivité devient une quête quotidienne. Les…

Erreurs fréquentes sur epicga es.com/activate et comment les éviter dès la première tentative
Un code d'accès saisi trop rapidement bloque l'activation pendant plusieurs heures, même…

Mobile Galaxy : les erreurs fréquentes à éviter avant de passer commande
Vingt-quatre heures d'attente pour la première charge d'un smartphone neuf ? Cette…

Sécurité : _popup peut-il exposer vos données de navigation ?
Oubliez la prudence de façade : chaque clic, chaque fenêtre pop, c'est…

Ytbmp4 gratuit : convertir une playlist YouTube complète en MP4
L'accès direct à l'ensemble des vidéos d'une playlist YouTube en format MP4…

168.0..150 : comment changer le mot de passe Wi-Fi pas à pas
Un code Wi-Fi laissé intact depuis la première mise en service, c'est…

168.1..109 ne charge pas : pare-feu, DNS, câble… où chercher la panne ?
Un simple point déplacé dans une adresse IP peut suffire à tout…

Comment transformer un scan jpj to PDF prêt à être envoyé par mail ?
Un fichier JPEG, une fois scanné, risque d'être trop volumineux ou d'afficher…

168.1..168 : les astuces pour retrouver l’adresse d’administration correcte de votre box
Une suite de chiffres mal alignés comme « 168. 1. . 168…

Pourquoi 192.168.1..85 s’affiche sans page web ? Les causes fréquentes
Saisir 192.168.1.85 dans un navigateur et obtenir un écran vide : voilà…
Reacher Saison 3 : date de sortie, acteurs et intrigue
La troisième saison de 'Reacher', la série à succès adaptée des romans…

Comment rattacher un forfait free mobile ?
Free mobile est un opérateur de téléphonie français. Lorsque vous êtes abonné…

Comment imprimer le bordereau Mondial Relay Le Bon Coin ?
Vous vendez des objets sur Le Bon Coin et vous souhaitez envoyer…
Samsung non enregistré sur le réseau : réglages cachés à vérifier en priorité
Sur certains téléphones Samsung, des paramètres réseau restent verrouillés malgré les réinitialisations…

Envie de passer à un iPhone 14 Pro Reconditionné pas cher sans risque ?
Le marché du smartphone reconditionné a vu ses ventes doubler en trois…
Exploration des outils gratuits d’IA pour améliorer votre productivité
À l’ère du numérique, optimiser sa productivité devient une quête quotidienne. Les…
