Plan de l'article
- Résumé
- Contexte de l’intelligence artificielle (IA)
- Qu’entend-on par « intelligence artificielle » ?
- L’IA n’est pas seulement une chose, mais pour la plupart, c’est l’apprentissage automatique appelé « machine learning ».
- Entraînement du réseau neuronal pour imiter un cerveau
- Le Deep Learning suscite un intérêt renouvelé pour l’IA
- Une machine auto-isolante ? Supervisé ou non supervisé contre renforcement vs transfert !
- Vous créez une machine avec de la mémoire pour plus de détails ?
- Quels sont les résultats suffisants pour l’apprentissage automatique ?
- Des forces qui parlent de l’apprentissage automatique
- Quelles sont les lacunes aujourd’hui ? Des problèmes de jouets, entre autres !
- Ce que nous avons étudié !
- Hypothèse 1 : Traitement du langage naturel (PNL) pour traiter l’anamnèse et les histoires de patients
- Hypothèse 2 : Les interfaces vocales et conversationnelles peuvent faciliter
- Hypothèse 3 : Vision par ordinateur pour visualiser, créer ou inspecter des images de manière machinale (parfois avec Deep Learning)
- Q&R éthiques
- Résultats
- Conclusion — que voulons-nous faire à l’avenir ?
- Annexe
Résumé
Vous trouverez ci-dessous un résumé de nos trois hypothèses, de ce que nous avons examiné et de réflexions à venir. Notre intention a été d’examiner l’offre des fournisseurs et d’examiner la façon de faire vous-même le travail de base.
Nous pouvons déjà affirmer ici que ce n’est pas l’intelligence artificielle (IA) avec laquelle nous avons travaillé, mais plutôt l’apprentissage automatique (ML). Les personnes qui semblent regarder sobrement le requin autour de l’IA semblent convenir que la ML est certes un sous-domaine de l’IA, dans les milieux universitaires, mais que nous devrons attendre au moins quelques décennies avant d’avoir une IA significative. Donc, dans le rapport, nous pouvons peut être lié à l’espoir qui existe avec l’IA à l’avenir, mais nous voulons être clairs que nous croyons que l’apprentissage automatique est un concept beaucoup plus approprié pour la situation actuelle des développements technologiques. Il est possible que même l’intelligence mécanique, utilisée dans certains contextes académiques, fixe les bonnes attentes.
A lire aussi : EvoluSEO : Quelles sont les fonctionnalités de cet outil SEO ?
Hypothèse 1 : traiter et comprendre l’anamnèse et les histoires de patients
Tout d’ abord, nous devons distinguer les concepts d’anamnèse et de narration du patient. Par exemple, ce rapport fait référence aux antécédents médicaux des professionnels de la santé, certes laissés par le patient au moment de la prise en charge, mais il s’agit d’une conversation guidée dans le but d’obtenir une bonne image globale, car nous voulons structurer l’historique pour fournir le contexte de ce que nous allons faire. L’histoire d’un patient, en revanche, est la façon dont vous la racontez plus spontanément et dans d’autres contextes. La raison pour laquelle nous devons faire la différence, c’est parce que nous avons des soins quantités avec anamnèse liée à des visites. En ce qui concerne les histoires, il peut aussi bien s’agir d’une application sous la forme d’un journal de santé, ou de sorte que ceux qui n’ont pas de gouvernance enregistrent leur état de santé. On peut dire qu’Anamnes est une information donnée à un certain moment et l’histoire de l’individu devient une information couvrant dans un certain temps.
Grâce à la technologie de compréhension du langage naturel, NLP (Natural Language Processing), nous pouvons déterminer de quoi une personne parle et ce qu’elle a pour les symptômes (via NER, Named Entity Recognition). De cette façon, nous pouvons examiner les usines de code médical, les plans de soins et les lignes directrices qui constituent une activité appropriée. Au cours de la pré-étude, nous avons principalement comparé l’anamnèse du codage thoracique ICPC (Classification internationale des soins primaires). Mais, bien sûr, la méthode peut être utilisée avec d’autres codeworks utilisés, tels que Sonomed CT, ICD-10 et KVÅ.
A découvrir également : Inconvénients du référencement : comprendre et les éviter
Lorsque nous avons évalué le service AWS d’Amazon pour NLP, il salue gentiment mais fermement qu’il ne prend pas en charge le suédois, et nous ne sommes pas sûrs de traduire automatiquement sans perdre ou fendrer des informations.
Cependant, il semble possible de rendre la NLP plus manuelle (et en suédois) grâce à des frameworks tels que NLTK (Natural Language Toolkit) et au traitement de ce que vous avez obtenu avec d’autres techniques de machine learning, telles que le Deep Learning.
Conclusion
L’un des principaux défis est l’absence d’informations structurées sur les diagnostics, les directives médicales, etc., qui peuvent être comprises par une machine. Si ce type d’informations était lisible par machine plutôt que comme des PDF, et que les machines pouvaient être explorées de la manière dont nous, les humains, pouvons explorer Wikipédia, nous pourrions accomplir beaucoup plus. Cela se fait à l’aide d’une technique appelée données liées. Certains qui ont compris cela sont le Social Board avec son aide à la décision médicale API Insurance.
Une thèse prometteuse a été présentée à Chalmers au printemps et vise à résumer des textes médicaux. Parmi les nôtres Nous comprenons qu’il s’agirait d’une solution extrêmement attrayante car leurs dossiers de patients ont tendance à être très longs et pratiquement impossibles à lire correctement pour chaque visite.
Hypothèse 2 : interface utilisateur vocale basée sur la conversation
S’appuyer uniquement sur une conversation vocale comme interface aujourd’hui ne semble pas possible, en suédois. Il y a souvent des idées fausses et la question est de savoir si vous gagnez quelque chose si l’utilisateur doit corriger manuellement ce qui a été dit. Nous avons principalement testé SiriKit d’Apple ainsi que Azure de Microsoft. Azure n’a pas compris ce que nous disions même lorsque nous avons choisi de lire une ligne particulière des films Parrain, même après trois tentatives, même s’il savait quelle était la ligne. Certes, le test a été effectué dans un environnement désordonné, mais il ne s’agit probablement pas d’une image sonore déraisonnable pour un scénario utilisateur réaliste, nous pensons.
Nous avons également évalué les enceintes intelligentes Google Home et Alexa d’Amazon vont réfléchir à l’équipement qu’un utilisateur pourrait disposer à la maison lorsqu’il doit prendre contact avec soin à l’avenir. Ces deux derniers ne parlent pas suédois, mais pour certaines langues plus petites du pays, des gadgets similaires peuvent devenir pertinents plus rapidement que pour la majorité des Suédois.
Ce que nous avons appris des tests avec des gadgets à commande vocale, c’est qu’ils sont fantastiques pour ceux qui, pour une raison ou une autre, ont du mal à écrire, à épeler ou à lire, mais qui peuvent parler très bien.
«Une évaluation commune est que 5 à 8 % des personnes dans la partie alphabétisée du monde ont des difficultés de lecture et d’écriture de nature dyslexique. » — Association suédoise de dyslexie
Et franchement, même nous qui n’avons pas de difficultés, nous avons probablement parfois des difficultés avec des mots que nous n’avons pas l’habitude de voir par écrit, mais savons comment cela s’appelle. Une interface basée sur la conversation ou à commande vocale peut rendre les soins plus accessibles aux personnes handicapées.
Conclusion
Notre conclusion est que l’on offre utilement la parole et les claviers lorsque du texte doit être saisi. Toutefois, lorsque la parole est utilisée, il faut avoir la possibilité de corriger le texte avant qu’il ne soit envoyé, utilisé ou stocké.
Hypothèse 3 : Vision par ordinateur et apprentissage profond
L’utilisation des services prêts à l’emploi des principaux fournisseurs de cloud pour une reconnaissance significative de l’image en médecine semble impossible. Nous avons particulièrement évalué Azure de Microsoft et AWS d’Amazon. Les rayons X sur les mains sont décrits comme « Un vase blanc sur une table ». Un homme recludé sur les Britanniques qui sont autorisés à gicler dans son bras est étiqueté comme « personne, à l’intérieur, assis, utilisant, femme, tenant, lit, table, main, haut, vert, jeune, blanc, coupant, nourriture, homme, jouant » où « utiliser » peut expliquer la seringue même si nous préférions voir l’étiquette « seringue ».
Conclusion
Cependant, nous pouvons toujours revenir en arrière et faire le travail nous-mêmes. Ensuite, les offres il s’agit de documenter mécaniquement la géométrie derrière une mauvaise tache hépatique, ou tout ce que l’on veut identifier. Cela semble se faire principalement avec des modèles évolutifs afin que l’on puisse détecter machinalement des objets (détecteurs de caractéristiques) et travailler avec des réseaux neuronaux (très probablement du genre convolutionnel). C’est une piste imaginable pour une continuation.
Récapitulatif
Malheureusement, nous pouvons constater un certain nombre d’obstacles :
- Le suédois n’est pas une langue prioritaire, ce qui rend difficile le travail avec la PNL ou l’achat de services. Il est possible que certaines de nos langues minoritaires obtiendront un soutien avant que ce soit pour le suédois.
- Ce contenu médical n’est pas reconnu dans les solutions finies des principaux fournisseurs.
- Il y a peu de produits prêts à l’emploi à acheter ou à louer qui sont utiles à tout ce qui est significatif. On parle souvent d’une incertitude quant à la responsabilité et au fait que les fournisseurs ne sont toujours pas vraiment déterminés. son modèle économique (peut-être parce qu’on ne sait pas très bien où se trouve la valeur la plus élevée).
Nous pouvons utiliser les principaux fournisseurs de cloud Amazon, Google et Microsoft, c’est d’embaucher de la puissance de calcul pour former nos propres modèles à l’apprentissage automatique. Des solutions prêtes à l’emploi, elles ne semblent pas avoir (encore), du moins pas dans un domaine médical.
La PNL est la plus prometteuse
Le plus prometteur pour une poursuite est le soutien à la décision dans le domaine des autosoins et de l’auto-triage, ainsi que la création de divers services d’information basés sur les désagréments de l’individu. Le triage est une méthode de tri et de hiérarchisation des besoins des patients en fonction de leur anamnèse, de leurs symptômes et parfois de données sur la fréquence cardiaque, la respiration, la température corporelle, etc. Dans une salle d’urgence, il s’agit généralement de la première évaluation que vous recevez avant de devoir attendre votre tour ou qui, dans les cas aigus, survient premier en matière de genre.
Anamnes est intéressante en combinaison avec la technologie NLP car nous pouvons ensuite faire correspondre anamnèse contre les vocabulaires médicaux tels que SNOMED-CT, CIM-10, CIPC et autres. Il offre une structure accrue du texte libre et peut ensuite mieux compléter les autres données lorsque nous formons un réseau de neurones.
Notre évaluation est que les fonctionnalités ML disponibles pour faciliter l’utilisation sur les services des fournisseurs de cloud ne sont pas encore prêtes pour une utilisation significative des images. Le suédois n’est pas non plus pris en charge en tant que langue au NLP, avec IBM à l’exception où trois des neuf fonctions du PNL sont également prises en charge en suédois.
En d’autres termes, nous devons assumer nous-mêmes une responsabilité technique plus importante si nous voulons faire en sorte que la ML se produise. Sinon, nous attendrons et espérons que quelqu’un d’autre résout nos problèmes pour nous. Mais l’utilisation de la même technologie disponible dans le reste du monde pourrait ne pas constituer une place de premier plan dans la santé mondiale d’ici 2025 ? Peut-être devons-nous tirer le meilleur parti de nos propres compétences uniques, techniques et nourrissantes ?
Ereworld Coll Conférence Vitalis 2018
Un peu décevant, c’est qu’aucune des solutions présentées sous la forme d’IA pendant Vitalis 2018 ne semble être parvenue jusqu’à être utilisée. En partie, ils semblent être basés sur de nombreuses informations structurées manuellement, sous la forme de protocoles de triage ou d’arbres de décision pour ceux qui sont techniquement posés, pour avoir une masse de connaissances, mais aussi que vous n’avez même pas utilisé de technologie établie pour permettre à la machine d’avoir une compréhension contextuelle.
Un exemple d’infirmière IA a suggéré que « champignon dans le bas-ventre » constitue une conversation continue pertinente sur le problème « mycose des ongles ». Une solution relativement simple autour de différents concepts de relation pourrait aider l’infirmière IA à dire que l’ongle et l’abcès ne sont pas significativement liés.
Plus impliqué lors de la prochaine étape
Plus positif, c’est que nous avons mis en contact avec un médecin de Sahlgrenska qui partage notre image sur la continuation et nous devons maintenant trouver des ressources pour un une évaluation à grande échelle qui est plus proche du secteur des soins. Dans le même temps, nous savons qu’il existe un projet de pré-étude dans la zone de conversion des services de soins numériques de VGR visant l’auto-triage. L’auto-triage est le résultat imaginable d’une telle entreprise, une autre est une deuxième opinion automatisée et un travail de qualité en général, car il devient relativement facile de trouver des écarts lorsque le diagnostic est inattendu par rapport à la signification de l’anamnèse ou de la réponse en laboratoire.
Nous avons été courtisé par le Bureau de l’innovation Chalmers et nous prévoyons une poursuite conjointe avec un chercheur de la PNL.
Compte tenu de ce que nous avons appris sur les possibilités du Deep Learning et les quantités d’antécédents de patients dont nous disposons, une combinaison de PNL et de Deep Learning semble ce sur quoi nous devrions nous concentrer dans un projet à plus grande échelle.
Nous espérons réunir les intérêts de plusieurs parties avec une prochaine étape commune, proche du secteur des soins, de sorte qu’il s’agira d’un atelier et d’un réalignement. en réalité !
Le résultat de ce projet de pré-étude est maintenant très clair. Nous avons trouvé un objectif et avons l’intention de le développer en recherchant des fonds auprès du Fonds d’innovation pour 2019, ainsi que nous rechercherons également d’autres financements de projets.
Contexte de l’intelligence artificielle (IA)
Sans parler de l’IA en tant que concept à plus long terme, nous nous référons à ce concept dans ce rapport appelé IA étroite (IA faible ou étroite). C’est-à-dire une IA spécialisée, non générale. Une machine qui fait bien une chose mais qui ne comprend pas d’autres choses qu’elle n’a pas rencontrées. On peut également choisir de considérer l’IA comme un domaine de recherche où l’apprentissage automatique est le numéro principal. En réalité, c’est plutôt l’apprentissage automatique que nous faisons dans cette étude préalable.
Comme presque tout est appelé IA aujourd’hui, il est difficile de trouver les grains d’or dans ce qui est proposé. Par conséquent, nous nous sommes intéressés à une étude préliminaire visant à examiner ce que c’était est « fini » et emballé dans l’IA dont nous pouvons profiter. En d’autres termes, nous cherchons à utiliser ce qui a déjà été fait sur ce qui est annulé, c’est-à-dire à correspondre à ce que les fournisseurs de différents niveaux possèdent et appliquent à nos sources de données.
Mais qu’entend-on par IA ? Une définition judicieuse de l’IA est celle qui a été souscrite dans les années 50, à savoir : « la capacité d’une machine à imiter un comportement humain intelligent »
Qu’entend-on par « intelligence artificielle » ?
«De plus, le marketing promet beaucoup plus que ce qu’il peut contenir, même en termes d’intelligence artificielle authentique. » — Difficile pour les acheteurs informatiques de trouver correctement quand tout s’appelle AI (Computer Sweden)
L’un des moyens de mesurer l’intelligence artificielle est le test Turing. Ensuite, un humain doit juger s’il parle à une machine ou à un humain. Mais on peut également discuter de ce que l’on entend par « intelligence ». Est-ce que vous le traduisez tout de suite en Suédois ? Le « renseignement » sera souvent déçu de ce que l’IA parvient à réaliser en 2018. Mais si vous le comparez plutôt à la façon dont l’ « intelligence » est incluse dans d’autres concepts ou domaines, comme la Business Intelligence (BI), le sens devient tout autre.
Mais d’autres nuances existent si vous regardez ce que dit un dictionnaire :
« La capacité d’acquérir et d’appliquer des connaissances et des compétences. »
Oui, une IA peut utiliser des outils d’apprentissage automatique basés sur les données avec lesquelles elle est alimentée.
On peut discuter de ce que l’on entend par « postuler », mais c’est sûr. L’application de ses connaissances peut être conforme à ceux qui croient qu’une IA doit avoir un corps ou une autre représentation, être consciente et mortelle pour être intelligente. Dans sa forme la plus banale, on peut également soutenir qu’un timbre à biscuits produisant en masse des baies de pain d’épice applique ses connaissances.
Mais qu’entend-on par « compétences » ? Est-ce qu’il peut vous dire qu’il ne peut pas tirer de conclusions fondées sur la base, ou qu’il ne pense pas que ce qu’il a appris puisse s’appliquer à la question qu’il a reçue ? Ce que nous cherchons avec ce raisonnement, c’est que l’intelligence nécessite peut-être plus que de simples vieux pouvoirs de calcul honorables.
« La collecte d’informations de valeur militaire ou politique » et « la collecte de renseignements »
Nous parlons ici de la similitude entre l’IA et la Business Intelligence. Il s’agit plutôt de connaissances, de familiarité et de perspicacité à travers l’information. Cette définition de l’IA nous pose quelques problèmes dans le projet. Si l’ « intelligence » en suédois devait porter sur la collecte de données, nous ne devrions raisonnablement pas manquer de compétences en IA, étant donné que c’est ce que tous les administrateurs de bases de données (DBA), de nombreux développeurs backend et tous les développeurs Fullstack ont fait pendant la majorité de leur carrière.
Indépendamment de ce que l’on considère comme une IA ou de la façon dont vous définissez l’intelligence, une machine n’est pas comparable à celle d’un humain. On peut s’attendre à ce que l’IA ait les capacités humaines, mais sa puissance de calcul est inhumaine depuis très longtemps. Mettez une machine à déterminer la moyenne de quelques millions de décimales et à comparer à un être humain, ou oui, vous n’aurez pas le temps de faire l’expérience de l’être humain fini.
L’IA n’est pas seulement une chose, mais pour la plupart, c’est l’apprentissage automatique appelé « machine learning ».
L’IA est un concept parapluie qui héberge, entre autres, l’apprentissage automatique (ML) et le résultat de ML, pour comprendre la parole humaine, avoir une machine pour avoir des concepts de choses visuelles comme un bord de circulation ambulante devant un véhicule autonome, et bien plus encore.
Mais la plupart d’entre elles, appelées IA, peuvent être classées dans le cadre de l’apprentissage automatique. Tout comme l’IA, l’apprentissage automatique a été défini dès les années 1950. Voici comment Arthur Samuel, en 1959, a pensé qu’il fallait décrire l’apprentissage automatique : « domaine d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmés »
Une définition plus contemporaine est la Aurélien Géron a écrit dans le livre Hands-on Machine Learning with Scikit-Learn et TensorFlow : « L’apprentissage automatique est la science (et l’art) de la programmation des ordinateurs afin qu’ils puissent apprendre des données »

Comme le note le site d’humour XKCD sur l’image ci-dessus, le processus d’apprentissage automatique est parfois un peu perfide, qu’on peut se perdre si on ne comprend pas tous les sous-moments. Ou comme l’a dit le journaliste Darrell Huff : « Si vous torturez les données assez longtemps, il avouera n’importe quoi » — Darrell Huff, le livre How to Lie With Statistics (1954)
Les statistiques étayant toute conclusion peuvent donc être obtenues. Le même problème existe avec l’apprentissage automatique, qui repose essentiellement sur les statistiques et les mathématiques. Il faut savoir Des que les données ne sont pas déséquilibrées, qu’elles sont préjudiciables, ont été torturées, etc.
Entraînement du réseau neuronal pour imiter un cerveau
Un réseau de neurones sonne plus fort qu’il ne l’est. C’est un réseau de neurones créé artificiellement. Les neurones peuvent aussi bien être appelés cellules cérébrales ou nerveuses. Ceux-ci s’interconnectent dans un réseau à l’aide de synapses et peuvent ainsi se parler entre eux.
Dans le cas de l’apprentissage automatique, ce « cerveau » est appelé réseau de neurones artificiels (ANN), donc un réseau de neurones créé.
Un neurone individuel est bon dans quelque chose et devient plus bien entraîné au fil du temps. Le rôle du neurone toiletté peut, par exemple, être de reconnaître votre grand-mère, d’où le nom de l’hypothétique « cellule grand-mère » :
« Dans les années 1960, le neurobiologiste Jérôme Lettvin a nommé l’idée du rire la théorie de la « cellule de grand-mère », ce qui signifie que le cerveau a un neurone dédié uniquement à la reconnaissance de chaque membre de la famille. Perdez ce neurone, et vous ne reconnaissez plus grand-mère. » — Un visage, un neurone (Scientific American)
Pensez que vous avez d’énormes quantités de neurones comme celui-ci. C’est ainsi que vous reconnaissez les amis et les parents que vous rencontrez souvent. Le réseau est décisionnel lorsque vous voyez quelqu’un que vous reconnaissez dans une foule.
Le neurone moins bien entraîné pourrait être d’essayer de reconnaître cette fille qui, en deuxième année, a déménagé dans une autre ville, avec laquelle vous n’aviez pas eu de contact depuis longtemps.
Le Deep Learning suscite un intérêt renouvelé pour l’IA
La raison pour laquelle l’IA est entrée dans la clameur est principalement due à la technologie appelée Deep Learning (DL). Le Deep Learning s’appuie sur n’importe quelle catégorie de machine learning, souvent mentionnée : apprentissage non supervisé, supervisé ou renforcé.
Ce que DL fait, c’est de disposer d’un réseau beaucoup plus complet que celui sur lequel on avait travaillé auparavant. C’est possible à la fois en raison de la puissance de calcul disponible aujourd’hui, du moins pour les grandes entreprises, mais aussi parce que de nombreuses s’est accaparé d’énormes quantités de données précieuses.
Normalement, de nombreuses couches masquées collaborent entre l’entrée et la sortie.
Ces niveaux que le Deep Learning possède beaucoup sont appelés pour des couches masquées (couches masquées) et le nom vient de ne pas le voir de la même manière que la partie où vous entrez les données (couche d’entrée) et la couche où la réponse sort (couche de sortie).
Chacun de ces calques cachés aide à affiner une impression, semblable à une image d’un parent pour savoir qui est dans l’image. Ou si une image doit être classée pour savoir si elle représente un chien ou un chat. Ou s’il s’agit d’une cellule saine ou malade que vous regardez.
Les réseaux de neurones peuvent avoir une architecture différente en fonction de ce qu’ils sont censés exécuter. Les couches masquées peuvent être des combinaisons de couches avec différentes spécialités. Par exemple, s’il faut rechercher des signes d’accident vasculaire cérébral parmi les photos de il facilite d’abord la localisation du visage dans l’image afin de permettre aux neurones subséquents d’avoir une zone délimitée pour localiser les paupières, le gypse buccal, les joues, etc.
Le Deep Learning bénéficie d’énormément de couches, ce qui le rend extrêmement complexe et intensif en calcul. Il n’est pas toujours réaliste de le faire soi-même ou d’investir dans sa propre puissance de calcul.
Une machine auto-isolante ? Supervisé ou non supervisé contre renforcement vs transfert !
Une fois que l’on a appris à une machine quelque chose basé sur des données, il existe deux architectures principales pour en tirer parti. La première est que vous pouvez avoir un réseau de neurones prêt à s’appuyer sur ce réseau appris à répondre aux questions. Supposons que vous envoyez une nouvelle image à un réseau de neurones formé à déterminer si l’image contient un chien ou un chat, alors vous obtiendrez une réponse.
Une architecture complètement différente permet d’économiser ces leçons à un modèle (ou modèle ML). Cela peut sembler délicat en suédois, mais il s’agit de « modéliser » les connaissances, de traduire la leçon en quelque chose qui peut être décrit à une machine. Et un modèle de connaissances (ML) peut être transféré d’une machine à une autre. Par conséquent, si une machine est formée à reconnaître quelque chose, elle peut être expliquée à une autre machine.
Qu’est-ce que l’on veut dire par apprentissage ? Dans l’apprentissage automatique, on parle le plus souvent d’apprentissage supervisé, non supervisé, de renforcement ou de transfert.
- L’ apprentissage supervisé (SL) est que l’ensemble de données avec lequel on alimente son réseau neuronal contient à la fois requête et facit, ou qu’il possède des « étiquettes ». Pensez à un enseignant pointant vers une carte de l’Europe et qui dit « c’est là que se trouve l’Allemagne, il y a l’Italie ». Après une formation, les neurones devraient commencer à répondre si un pays est l’Allemagne ou l’Italie.
- L’ apprentissage non supervisé (UL) signifie ne pas avoir un œil de la même manière mais souhaite que le réseau lui-même détecte des modèles dans la source de données. Pensez à un enfant assis avec une grande quantité de blocs Lego. Comment l’enfant arrive-t-il à savoir si les blocs s’adaptent ensemble ? S’agit-il de la taille, de la couleur, de la forme ou de toute autre chose cruciale ?
- L’apprentissage par renforcement (RL) consiste à encourager ce qui est bon et qu’il y a une sorte de conséquence à ce que vous voulez éviter. Un exemple révélateur est d’apprendre à faire du vélo. Le sentiment de liberté lorsque vous parvenez à vaciller vers l’avant est la récompense et la douleur du survol du vélo est ce que vous essayez d’éviter. Ou dans les langages technologiques, vous disposez d’une fonction de récompense et d’une fonction de coût qui contrôle le comportement souhaitable dans la bonne direction.
- L’apprentissage par transfert (TL) consiste à transférer un modèle de connaissances dans un domaine plus ou moins nouveau afin de résoudre des problèmes autres que prévu initialement. Il a été démontré qu’il s’agissait d’abord d’entraîner un modèle ML sur l’identification des fleurs, des chats et d’autres objets vivants, pour ensuite peaufiner la classification du cancer de la peau dans les diagnostics d’imagerie médicale.
Apprentissage non supervisé, le moins adapté aux soins ?
L’ apprentissage supervisé fonctionne pour l’exemple de la source de données que nous avons reçue sur le thoracique. C’est parce que nous avons une anamnèse ainsi que trois codes de diagnostic médicaux différents basés sur l’historique qu’ils ont lu. Non supervisé est un peu plus difficile, alors vous vous asseyez simplement sur un tas de données, mais vous n’avez pas de réponse donnée quant à ce que chacun des points de données implique. Imaginez que vous ayez beaucoup d’histoires de patients, mais que vous n’ayez aucune idée du diagnostic, ni même de celles qui ont été malades, même à leur avis.
Nous supposons que, dans les cas où les soins ont collecté des données sur l’état de santé des patients, il est dans l’intention de poser un diagnostic plutôt que de devoir accumuler des informations. Nous supposons donc que nous nous asseyons à la fois sur la question sous forme de réponses d’échantillons, d’anamnèse, de radiographies et d’autres données, ainsi que tout type d’évaluation ou de classification.
Dans ces cas, il n’aurait pas de sens de prétendre que nous ne connaissons pas la réponse. Toutefois, les renforts supervisés et les renforts peuvent toujours être pertinents. Si vous les affrontez les uns contre les autres, ils semblent avoir des ambitions différentes. L’apprentissage supervisé consiste à faire en sorte qu’une machine devienne aussi capable que les personnes qui l’instruisent, alors qu’avec le ciment de rène, vous ne vous limitez pas nécessairement à ce que les instructeurs sont capables.
L’apprentissage par renforcement est très susceptible de poser des problèmes limités, tels que la mise en place d’un cadre réglementaire délimité. Il n’est pas clair dans quels cas cela fonctionnerait dans un contexte de soins.
Vous créez une machine avec de la mémoire pour plus de détails ?
Une blague parmi les développeurs est qu’il n’y a pas de différence entre une IA et un programme avec un millions d’incisions aux scénarios. Ce que nous, les développeurs, appelons les théorèmes. Une déclaration if est comme une condition. En quelque sorte, s’il y a du rôti de silex dans le magasin, achetez à la fois du rôti de silex et de la salade de pommes de terre pour le dîner. Si une machine a des millions de règles de ce type à gérer, il peut commencer à devenir difficile à distinguer d’un être humain dans certains cas.
Est-ce suffisant pour faire du bien et est-ce que ce que nous voulons dire est intelligent ?
Quels sont les résultats suffisants pour l’apprentissage automatique ?
De nombreux services basés sur l’apprentissage automatique ont au mieux une meilleure précision que les gens, mais dans quelle mesure faut-il être défendable sur le plan éthique ? C’est une question difficile. De façon anecdotique, dans le dialogue avec des collègues, il semble y avoir un consensus selon lequel, au cas où une machine se trompe lorsqu’elle est épouvantable et dévastatrice. pour la confiance, alors que toute l’humanité n’est pas jugée aussi facilement par les erreurs que nous sommes déjà habitués. Cela ne semble ni juste ni rationnel.
Comment déterminer si les solutions techniques produites sont suffisamment bonnes ? Oui, il y a différents critères. Une chose qui est à saisir pour tout le monde est si souvent que vous surpassez les professionnels que vous avez remplacés certaines des fonctions de l’homme. Que cela se produise, on peut en lire périodiquement. Il n’est pas rare qu’une machine soit plus résistante aux points qu’un humain lorsqu’il s’agit d’identifier l’une ou l’autre. Un critère plus statistique est de savoir si l’on peut influencer l’entropie relative d’une quantité d’information. C’est un moyen de savoir si les informations traitées par un algorithme ont atteint un ordre plus élevé ou non. Les geeky peuvent également en savoir plus sur l’indice de diversité.
Un grand nombre de diagnostics d’images semblent pouvoir être réalisés à partir des modèles de connaissances/réseaux neuronaux qui résultent de différentes formes. de machine learning. Comme aider un humain à trouver des « régions d’intérêt (ROI) », des endroits dans une image où l’homme devrait se concentrer.
Des forces qui parlent de l’apprentissage automatique
Une machine a certaines super capacités qu’un humain a du mal à atteindre. L’un d’entre eux est que les machines n’ont pas d’hypoglycémie avant le déjeuner et ne sont pas fatiguées à la fin de la journée de travail. Ils peuvent simplement travailler la nuit et présenter leurs résultats lorsque vous avez choisi de bien dormir, en prenant un matin de sommeil caritatif et une balade à vélo saine au soleil pour aller travailler.
Contrairement aux humains, la puissance de calcul des machines augmente d’année en année. Et dans certains cas, vous pouvez investir quelques dizaines de milliers de billets et obtenir la réponse à une question la même semaine au lieu de la prochaine décennie. Aujourd’hui, ce sont soit les GPU (GPU, Graphic Processing Units), les processeurs Tensor (TPU, Tensor Processing Unit) loués par Google, soit le FPGA (Field) d’Intel Gate Array programmable), qui fait le travail rugueux. Ou oui, ce sont plutôt des halls de données remplis par ces utilisateurs. Ou avec sa propre station de travail avec un GPU similaire à la CUDA de Nvidia pour passer en tant que scientifique des données, de l’exploration de sources de données à l’échantillonnage d’un réseau neuronal artificiel sur un sous-ensemble de données. Il s’agit d’examiner si la possibilité de continuer à plus grande échelle est intéressante.
Quelles sont les lacunes aujourd’hui ? Des problèmes de jouets, entre autres !
L’une des difficultés à tirer parti de l’apprentissage automatique aujourd’hui est que de nombreux fournisseurs croient proposer des solutions toutes faites, mais après une inspection plus approfondie, ce n’est peut-être pas aussi révolutionnaire que le message commercial.
Un autre défi semble être que de nombreux fournisseurs proposent des solutions aux « problèmes de jouets ». Des solutions à des choses qui n’aident pas beaucoup. Cela est clair avec les services cognitifs qui inspectent les images. Quand ils ne peuvent que s’identifier des célébrités internationales ou des monuments comme la Tour Eiffel, ils ne sont pas si utiles pour les soins, ni presque n’importe quelle industrie.
Bien que les fournisseurs disposent de longues listes de services plus ou moins prêts à l’emploi, on ne sait pas clairement ce qu’ils offrent qui ne concerne ni la puissance de calcul classique ni les problèmes de jouets. Vous pouvez avoir l’impression que de nombreux fournisseurs se disent plus élevés dans la chaîne alimentaire qu’ils ne le sont réellement.
Une autre difficulté consiste à travailler avec la gestion des modèles de connaissances/réseaux neuronaux formés. Il faut de l’expérience que beaucoup manquent encore de choisir une stratégie autour de l’apprentissage en ligne, de l’apprentissage par lots ou si vous jetez tout à chaque itération et recommencez à zéro. Comparez-vous au cas où vous lobotomatez/réinitialisez vos collègues humains chaque fois qu’ils sont censés apprendre quelque chose de nouveau. Sans doute pas.
Il aurait été approprié de pouvoir s’appuyer sur les connaissances d’autres personnes et sur des modèles de connaissances prêts à l’emploi. Peut-être que cet homme ? ont déposé leurs modèles et leurs données ouvertes (liées) dans une chaîne de blocs d’audience ? Pour le moment, c’est sur le service développeur Github que l’on trouve le plus souvent des solutions prêtes à l’emploi à réutiliser, certes avec une qualité variable.
Ce que nous avons étudié !
Nous avons examiné ce qui est offert sous la forme de solutions prêtes à l’emploi par les intervenants du secteur des soins, mais également les fournisseurs de technologies les plus classiques et leurs systèmes cognitifs et IA qui peuvent être utilisés par le biais de leurs services en ligne.
Certains produits sont proposés sous forme de marque blanche. Cela signifie que vous pouvez encadrer votre propre logo sur une solution autrement finie. Dans le même temps, l’un des deux fournisseurs qui ont entendu parler d’eux-mêmes après Vitalis explique que :
« Malheureusement, nous ne disposons pas d’une documentation technique complète si généralement nous ne proposons pas de produit contre les développeurs ou les intégrateurs système, mais que nous sommes plus habitués à fournir des solutions globales finies avec UI backend. »
Avec d’autres en mots, la transparence de la solution n’est pas meilleure que de devoir tester manuellement l’exécuter pour chaque diagnostic imaginable et voir au cas où le résultat semble logique. L’autre fournisseur qui a « osé » entendre parler aimerait idéalement organiser une réunion pour régler les questions auxquelles répondre, même si les questions sont déjà apparues dans la conversation, dans la liste à puces et toutes…
Pour en savoir plus sur la complexité de ces solutions, nous avons également étudié des cours pour développeurs ainsi que des certificats en Deep Learning, en vision par ordinateur, en NLP et en GAN sur des plateformes de cours telles que Udemy, ainsi que la science des données à Berkeley chez EDX. Voici un peu ce que nous avons trouvé dans l’hypothèse respective.
Hypothèse 1 : Traitement du langage naturel (PNL) pour traiter l’anamnèse et les histoires de patients
L’exemple de source de données que nous avons sur le thorax contient une anamnèse dans un texte non structuré, trois diagnostics individuels de médecins différents avec classification diagnostique selon le code du CIPC, ainsi que ce que les trois les médecins sont arrivés ensemble.
Nous avons examiné la source de données sous deux angles différents. En partie à travers la PNL avec une analyse du sentiment similaire associée, voyant des indications positives et négatives (correspondance douce). Une option plus accessible s’est avérée être la correspondance de mots entre le codework du CIPC et le texte de l’anamnèse (correspondance difficile). La correspondance douce peut capturer des mots qui décrivent une expérience générale de l’état de santé, mais qui ne semblent pas arriver à quoi que ce soit qui pourrait être facilité dans une situation de soins.
La PNL est mathématique, mais le langage est très varié. Cela rend quelque peu compliqué la mise en œuvre de la PNL dans les soins, étant donné le besoin de contrôle qui existe pour le fournisseur de soins de santé d’assumer la responsabilité.
En collaboration avec des experts en psychiatrie du Sahlgrenska University Hospital, nous avons examiné des solutions qui existent pour résumer et naviguer dans les textes de journaux. Malheureusement, nous avons également eu de la difficulté à relier une solution existante à quelque chose qui peut être mis en œuvre. Peut-être devons-nous le faire au lieu de cela, approcher le milieu universitaire pour apporter quelque chose de la recherche avec nous à quelque chose que nous pouvons évaluer et produire plus tard avec l’industrie ?
Nous avons lié des contacts au sein de Chalmers par l’intermédiaire de leur bureau d’innovation pour parler spécifiquement de la PNL. Nous avons également interviewé un chercheur en biologie computationnelle et en biologie des systèmes axés sur la physiologie de l’Université de Göteborg et du Laboratoire Wallenberg afin d’obtenir des informations et des perspectives.
Mais nous avons remarqué que dans l’ingénierie et la PNL, il existe des ressources à Göteborg. Par exemple, cette thèse de mars mérite d’être explorée :
« Dans le document III, nous étudions l’utilisation de modèles de séquences neuronales profondes travaillant sur le flux de caractères bruts comme entrée, et comment cette classe de modèles peut être utilisée pour détecter des termes médicaux dans le texte (tels que les médicaments, les symptômes et les parties du corps). Le système est évalué sur les dossiers médicaux en suédois. » — La contestation d’Olof Mogren au Département des données de Chalmers
Science d’interprétation de ce qui est dit ou écrit
Certaines organisations ont présenté ou donné des conférences lors de la conférence Vitalis 2018. Ou plutôt qu’ils avaient créé des solutions à l’interaction utilisateur basée sur la conversation (que nous allons passer sous peu). Aucun d’entre eux n’a impressionné. Certains d’entre eux semblent avoir une spirale auto-renforçante et négative où ils utilisent l’apprentissage par renforcement sur l’anamnèse qu’ils ont générée eux-mêmes. Elle devrait devenir une IA de plus en plus stupide au fil du temps, dite surajustée, même s’ils ont donné des conférences sur le fait que leur IA devient plus intelligente de jour en jour. Peut-être ont-ils oublié de vous dire comment c’est devenu plus intelligent malgré l’impression de ce qui semblait auto-renforçant ?
Entre autres choses, Region Skåne a construit un prototype de ce à quoi pourrait ressembler un tel service (voir ci-dessus). Mais là, vous avez probablement assumé les besoins du soignant lorsque vous avez quelques sous-moments avant d’arriver à pour décrire leur état de santé. Ainsi, il s’agit d’une solution à la réservation de temps, où seulement plus tard dans le processus de réservation d’un rendez-vous demande comment le patient voit son cas.
Cependant, il reste à fournir un soutien décisionnel autour du niveau de soins approprié, ce qui complète les soins primaires existants, fixés via le réseau. Vous manquez donc l’auto-triage à moins d’essayer de prendre une décision en fonction de ce que vous savez. Avec la solution qui conduit l’utilisateur à effectuer une réservation de temps avant de connaître le niveau de soins approprié (le cas échéant), on manque le point. C’est un service de réservation de temps.
Si vous supposez qu’Agnes Wold a raison dans son exemple, il est stupide que, dans ses solutions numériques intelligentes, vous orientez les gens vers une réservation de temps inutile alors qu’ils devraient encourager certaines personnes à rester à la maison ou simplement attendre.
Pour Pour qu’il fonctionne avec une sécurité de frappe plus rassurante, la masse de soins doit être annoblée et lisible par machine, afin que vous sachiez quelles questions de suivi doivent être posées à l’utilisateur. Pour cela, les protocoles de triage semblent être utilisés aujourd’hui. Traduit en ML, il correspond à un arbre de décision. La valeur d’entrée correspond à l’histoire ou à l’anamnèse du patient et, en fonction de son contenu, le cas peut prendre des chemins légèrement différents. Il existe des signes de maladie pulmonaire, on se retrouve dans cette partie de l’arbre et il faut poser certaines questions de contrôle. S’agit-il plutôt de douleurs articulaires, il y a d’autres questions de contrôle pour pouvoir poser un diagnostic.
Est-ce grave pour le patient ?
Grâce à des technologies telles que l’analyse des sentiments, on peut obtenir une indication de l’émotivité dans le récit du patient. Comme lors de l’étude préalable, nous n’avons pas accès à de plus grandes quantités d’histoires de patients, nous avons plutôt submergé cette dernière avec une source de données différente. Nous avons examiné les avis sur les produits où nous avions deux extrêmes : ceux qui ont donné une bonne note et ceux qui ont donné de faibles notes. En plus des évaluations, nous avons le texte de la revue. En formant un ML sur ces données, il peut prédire l’évaluation avec une certaine certitude si vous l’alimentez avec un nouveau texte de révision.
Une parabole de soins serait d’avoir une source de données d’histoires historiques de patients avec une sorte de corroboration au cas où le cas serait de nature grave ou inoffensive.
Ce type de technique peut être incertain dans chaque cas, mais peut peut-être capturer les extrêmes où le désespoir brille et où une sorte d’action est justifiée.
Classificateurs Adaptive Boosting (Adaboost) et Cascading
Les classificateurs AdaBoost et Cascading sont des méta-algorithmes en ML et des techniques qui fournissent une « opinion » compilée basée sur de nombreux signaux du réseau neuronal. C’est une façon de la machine de trouver une estimation qualifiée au lieu de se contenter de la comptabilité. probabilité. Un équivalent de « beaucoup suggère que… », que beaucoup d’indications moins importantes pointent vers une conclusion particulière.
Pour cela, nous ne disposons pas non plus d’une source de données appropriée. Nous avons donc étudié comment effectuer une classification binaire pour déterminer si un texte est du spam ou non. Lorsque vous alimentez un modèle ML avec un texte particulier et que vous demandez une réponse avec AdaBoost et une autre sans, il s’avère qu’AdaBoost fonctionne souvent mieux. Mais ce n’est pas toujours le cas.
Il est possible que l’incertitude diminue avec la quantité de données. Quoi qu’il en soit, il est judicieux d’en tenir compte pour la source de données avec laquelle on travaille et d’évaluer la précision.
Analyse sémantique
La technique d’analyse sémantique latente (LSA) peut être utilisée pour calculer la parenté entre les mots. Il existe une multitude d’applications de LSA, mais dans un contexte de soins, entre autres, une gestion intelligente du synonyme pourrait être utile. Comme avoir une relation entre médecin → médecin. Un autre domaine imaginable est que classer les textes.
Certains services comme celui-ci peuvent être achetés en ligne, Infermedica par exemple :
« L’API Infermedica dispose d’une technologie personnalisée de traitement du langage naturel, permettant à vos applications de comprendre les concepts cliniques (symptômes et facteurs de risque) mentionnés par les utilisateurs comme texte en langage naturel. »
« Déduire », tirer des conclusions ou indiquer quelque chose, est peut-être clair quant à la précision que l’on peut attendre des conclusions. Il s’agit d’une tentative de traitement de l’information.
Poursuite de la piste PNL : Deep Learning NLP combiné
Pour réduire le risque que les conclusions soient imprécises, nous devons continuer à explorer les possibilités. Nous croyons qu’une combinaison de grands ensembles de données, de Deep Learning et de PNL constitue la prochaine étape logique.
Malheureusement, le Deep Learning nécessite beaucoup plus de données que ce que nous avons accès dans cette étude préalable. Toutefois, la quantité d’informations ne pose aucun problème. pour VGR, plutôt d’être autorisé à l’utiliser. La prochaine étape consiste donc à élargir le projet avec davantage de parties, à travailler avec des experts de Chalmers et de l’Université de Göteborg afin de produire une spécification à quoi ressemble une source de données appropriée.
Hypothèse 2 : Les interfaces vocales et conversationnelles peuvent faciliter
Cela se passe sous ML en raison du fait qu’il faut beaucoup d’apprentissage automatique à une machine pour décoder la parole humaine et au mieux comprendre l’intention de l’homme avec ce qui est dit. Il peut également s’agir d’écouter comment quelque chose est dit, quelles parties sont soulignées avec emphase, si la façon de respirer pendant qu’elle parle suggère quelque chose, etc.
L’interprétation de Siri de l’alimentation nasale « a un peu mal à la tête mais se porte probablement très bien » n’est pas entièrement parfaite.

Image 7 : L’interprétation de Siri de l’alimentation nasale « a un peu mal à la tête mais se porte probablement très bien » est pas complètement parfait.
Nous avons évalué les services et effectué des recherches. Pour ce qui est de parler et d’être compris, les résultats sont très différents. Dans tous les cas, la compréhension a été traitée dans les propres systèmes des fournisseurs. Nous devons donc supposer qu’elle ne s’améliore pas actuellement.
Siri d’Apple pense que « faire assez » est « sacrément hor » lorsqu’on parle par une personne nasale avec un léger accent nourrissant, mais la même application fonctionne relativement bien lorsque d’autres en parlent.
Nous avons également testé ce que Microsoft offre via Azure. Là, il fallait déterminer la compréhension de la machine en choisissant une phrase à répéter. La machine savait donc à l’avance ce qu’elle allait entendre. Malgré cela et trois tentatives pour parler d’une réplique du premier film de la série Godfather, la machine n’a pas entendu ou compris le discours. Si vous considérez qu’il s’agit de circonstances atténuantes, c’était la même alimentation nasale que, à cette occasion, était assise dans un café à moitié plein et assez dense dans le nez que d’habitude compte tenu du premier jour « sain » après un rhume. Cependant, pour que les soins puissent utiliser ces services, on ne peut manquer d’aider ni le nez ni le rhume, et les nutriments doivent également être aidés.
Soutien à domicile pour parler
Ce que nous avons appris de quelques semaines avec Google Home et Amazon Echo (mieux connu sous le nom d’Alexa), c’est qu’aujourd’hui ils ont du mal à faire avec tout ce qui est suédois. Même si vous acceptez de leur parler anglais, il n’est pas tout à fait simple de choisir comment prononcer les choses suédoises pour qu’elles comprennent. Par exemple, il est étonnant de pouvoir demander à Google Home des choses comme la fermeture de la pharmacie la plus proche. Mais s’il faut demander quand la pharmacie d’une rue particulière ferme, des questions se posent sur la prononciation, ou s’il faut essayer de traduire, ou bien d’autre.
Écoutez ce que demande la maladie ?
La plus grande diffusion médicale que nous ayons atteinte pour l’utilisation des interfaces vocales est le conseil pour contacter, entre autres, Araz Rawshani de l’Université de Göteborg. Ce que nous comprenons, c’est la recherche sur la façon dont une personne sonne qui est en train de subir un arrêt cardiaque ou qui risque beaucoup de subir un arrêt cardiaque et qu’Araz est susceptible de nous orienter à ce stade. Sauf qu’il s’agirait d’un bon signal d’avertissement à intégrer dans nos services de téléphonie, car lorsque nous appelons 1177, il serait intéressant d’évaluer en tant que fonctionnalité préventive, par exemple, dans les applications que nous produisons pour parler de son récit patient. Ou en cas d’auto-triage. Apparemment, il existe des biomarqueurs qui affectent la respiration et la parole.
Une application concevable est une aide au triage. Guide de prise en compte des accidents mineurs dans la cuisine, qui guide l’utilisateur à suivre l’ordre des enquêtes existantes. Conseils d’amateurs qui, via des technologies de conversation, peuvent assurez-vous de vous remettre en état avant de contacter éventuellement le soin pour une vérification postérieurement.
Conclusion
La conclusion de cette hypothèse est qu’il y aura peut-être une solution conversationnelle efficace à l’une des langues minoritaires suédoises avant de l’obtenir en suédois. Ensuite, si dans certaines applications de soins à distance, il y a des points que le patient devrait pouvoir parler aux appareils, cela semble être évalué.
Les groupes qui peuvent bénéficier grandement des interfaces basées sur la conversation sont ceux qui ont des difficultés de lecture et d’écriture. Ce qui, selon l’Association suédoise de dyslexie, est estimé à environ 5 à 8 % de la population de la partie alphabétisée du monde. Dans l’intérêt de ce groupe, il est préférable que la saisie de texte soit effectuée à l’aide d’éléments basés sur la conversation, par exemple, pour les concepts que vous pouvez savoir comment ils sont prononcés mais que vous ne pouvez pas épeler. De plus en plus de personnes en bénéficieraient de temps à autre.
Aujourd’hui, c’est un peu difficile à utiliser. ces services par l’intermédiaire des fournisseurs connus pour des raisons de confidentialité. Offrir un service où tout ce qui est parlé est envoyé à un tiers pour analyse rend la question plus juridique.
Un scénario plus facile à marcher est de faire lire des textes, ce qui peut profiter à la fois à ceux qui ont une capacité de lecture réduite, mais aussi à toute autre personne qui, pour une raison ou une raison, préfère ne pas lire pour le moment. Par exemple, obtenir vingt articles de 1177.se chargés en tant que livre audio personnel face à un certain traitement.
Hypothèse 3 : Vision par ordinateur pour visualiser, créer ou inspecter des images de manière machinale (parfois avec Deep Learning)
La vision par ordinateur est l’un des nombreux concepts qui impliquent de donner à une machine la propriété de voir quelque chose. Cela ne revient pas toujours à la façon dont un humain voit quelque chose, mais nous y reviendrons un peu plus tard.
Les images, et surtout les vidéos, permettent à une machine d’analyser par rapport au texte et les chiffres. L’équivalent d’une prise de vue unique que vous prenez avec l’appareil photo de votre téléphone portable peut être n’importe quel livre que vous avez lu pendant vos heures de classe. Étant donné que la vision par ordinateur est si intensive en calcul, il est préférable de pouvoir s’appuyer sur l’autre déjà fait. Pour cela également, il existe des services en ligne, dont nous avons inspecté certains d’entre eux.
Parmi les principaux fournisseurs de solutions plus ou moins prêtes à l’emploi sur le net, il y a un certain ensemble de fonctionnalités standard. La liste suivante contient la liste Microsoft pour son service cognitif Azure :
- Prenez des images en fonction du contenu.
- Catégorisez les images.
- Identifiez le type et la qualité des images.
- Détectez les visages humains et renvoyez leurs coordonnées.
- Reconnaître le contenu spécifique à un domaine. (Pour l’instant, seules les célébrités et les célèbres monuments)
- Générez des descriptions du contenu.
- Utilisez la reconnaissance optique des caractères pour identifier le texte imprimé présent dans les images.
- Rereconnaître texte manuscrit.
- Distinguer les jeux de couleurs
- Signaler le contenu adulte.
- Recadrez les photos à utiliser comme vignettes.
Sur la base de ces services, il existe un risque de créer des attentes élevées quant à ce que ces services font face. Assez pour que beaucoup de temps et d’énergie aient été consacrés à la mise au point des capacités de ces services, mais à quoi peuvent-ils être utilisés dans la pratique ? Nous avons un peu fait des essais. La première sortie a été le service Rekognition d’Amazon. Une photo de Marcus assis à une table debout donnant des conférences sur un tissu de projecteur a reçu un thème clair par rail et militaire. Peut-être que l’embrayage du train était dû à des fenêtres inclinées en arrière-plan, mais l’armée a probablement besoin de plus d’imagination.
La deuxième étape consistait à demander aux services cognitifs de Microsoft sur Azure de vous parler un peu de quelques photos.
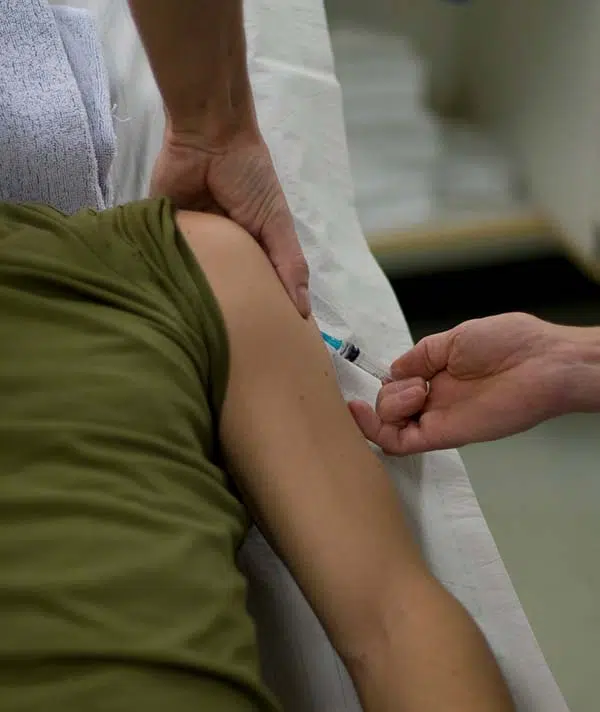
L’homme qui se fait une seringue dans le bras est assis ou est certes allongé sur une sorte de lit, mais « utilise » une référence à la dépendance plutôt qu’à un scénario hospitalier ? N’importe quel tissu blanc pourrait autrement révéler un endroit probable.
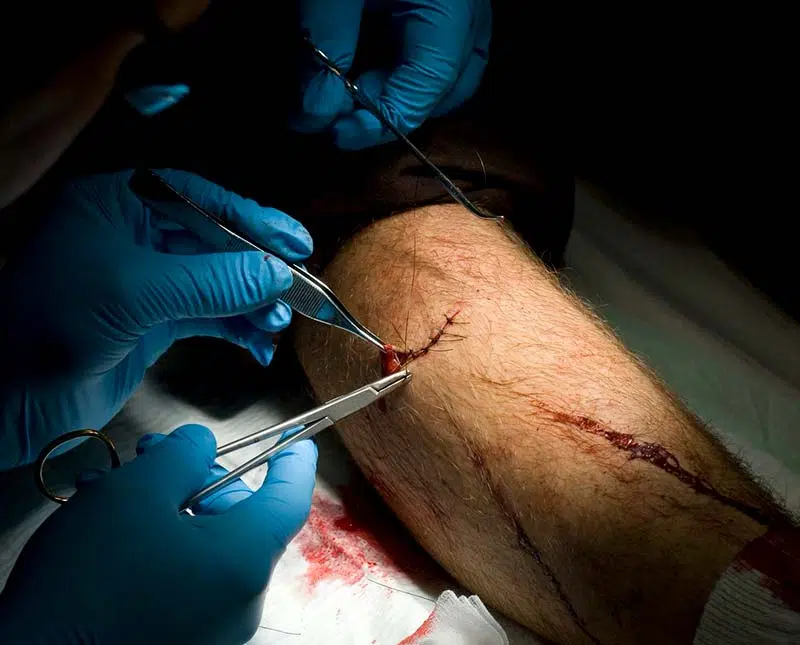
Non, ce n’est pas une personne qui tient une batte de baseball sur cette photo. Cependant, certaines balises sont assez descriptives, par exemple, qu’il fait sombre et que ce qu’il faut penser que la coupe implique. Mais le gâteau est intéressant. Est-ce la surface blanche sanglante qui ressemble à un gâteau aux fraises ? Ou s’agit-il d’un accident sur la piste de ski et de la raison du « ski » ?
De quoi dépendent ces bizarreries ? Probablement que le substrat des images n’est pas très complet les utilisations que nous recherchons dans nos soins.
L’IA souffre d’hallucinations : les réseaux neuronaux rêvent-ils de moutons électriques ?
Comme le site Web AiWierdness a attiré l’attention en mars 2018, les réseaux neuronaux semblent souvent voir des moutons en images même s’il n’y en a pas. Un peu une inclinaison comique de la nouvelle de science-fiction « Do Androids Dream of Electric Sheep ».
Les photos ci-dessous (empruntées par Aiwierdness.com) semblent identifier les points lumineux qui apparaissent sur des photos avec du contenu vert, probablement de l’herbe.

L’explication simple est suffisante pour que le matériel d’imagerie formé par le service on avait souvent la combinaison de pelouses et que les soirées brillantes n’étaient que des moutons. Ainsi, lorsque les images sont accompagnées de taches brillantes de neige qui décongelent sur un sol semi-vert, il semble facile de penser qu’il y a de petits moutons laineux.
D’autres erreurs de classification récurrentes que nous avons remarquées sur les photos que nous avons exécutées contre Azure de Microsoft sont que les anciens bâtiments en pierre sont souvent supposés avoir une tour d’horloge. Pour éviter le travail technique, vous pouvez suivre Picdescbot sur Twitter. Dans ce cas, une image aléatoire est extraite de Wikipédia et vérifie ce qu’un service d’imagerie suppose qu’il imagine. Souvent, les choses vont bien, avec un certain nombre d’exceptions étranges et parfois comiques.
Une hallucination plus régionale est que Microsoft Azure pense souvent qu’il s’agit d’une pizza en photo lorsqu’il publie des photos de presse tirées des événements auxquels les politiciens de VGR sont venus. Jusqu’à présent, il n’y a pas eu de pizza en photo.
Le champ d’utilisation de ces services prêts à l’emploi n’est actuellement pas lié aux soins. Possiblement on loue de la puissance de calcul et forme un service sur le type d’images que vous souhaitez pouvoir comprendre.
Plus de vision manuelle par ordinateur
Si vous optez plutôt pour une vision par ordinateur un peu plus manuelle, vous devez faire face à de nombreux défis. Comme mentionné précédemment, il faut beaucoup de puissance de calcul. L’objectif initial est donc de limiter les informations avec qui vous devez travailler. On souhaite identifier un retour sur investissement (région d’intérêt), éventuellement traduit en diapositives en suédois.
Ce n’est pas plus étrange que d’identifier certaines formes géométriques basales pour voir si une image contient quelque chose qui pourrait être intéressant
L pré-entraîné pour détecter l’emplacement du visage, des yeux et de la bouche dans un flux d’image/vidéo. Il ne supporte apparemment pas la barbe entière, un rectangle rouge devrait marquer la bouche.
Traduit en un exemple simple sous forme de reconnaissance faciale, il s’agit de la combinaison d’un ou de plusieurs yeux, les sourcils, le nez, la bouche et les oreilles qu’il accroche qui forment un visage. Toutes ces propriétés sont dites des classificateurs faibles, c’est la combinaison de plusieurs choses qui rendent une machine convaincue que ce qu’elle voit est un visage.
Souvent, ces décisions sont prises sur des images en niveaux de gris car les nuances de couleur n’ajoutent rien aux machines, ce que nous, les humains, bien sûr, ne sommes pas d’accord. La sécurité des points d’une machine n’est pas nécessairement augmentée en voyant la couleur des yeux ; en revanche, les informations sur les couleurs sont onéreuses dans le calcul.
La géométrie du visage dans une forme simplifiée, consultez la photo ci-dessus et l’image à côté, et considérez les points ci-dessous :
- Selon une machine, le nez est généralement un tiret verticalement lumineux entouré de deux stries verticales plus sombres. Ainsi, un nez peut être simplifié à la largeur de trois pixels.
- Un œil est généralement une tache sombre avec des yeux blancs. de part et d’autre. Chaque œil peut être simplifié à trois pixels, où le point sombre doit se situer entre deux pixels plus lumineux.
- Les sourcils sont deux stries horizontales avec une certaine direction l’une par rapport à l’autre. Comme le nez, il est souvent collé avec un tiret sombre au milieu et des stries plus claires autour, et non dans la même direction que le nez.
- La bouche est simplifiée par trois stries, une noire entourée de deux stries plus claires pour les lèvres. La bouche a la même direction que les sourcils.
La géométrie possède également des relations internes qui expliquent qu’il s’agit d’une face. On peut s’attendre à ce que le nez se trouve à un endroit particulier si l’on croit avoir trouvé la bouche ou les yeux. De cette façon, on peut identifier un visage même si la personne se tord la tête ou se tient debout sur ses mains. Ou si, comme sur la photo ci-dessus, il est difficile de discerner la bouche en raison de la croissance de la barbe, d’autres classificateurs faibles peuvent piéger un impératif commun selon lequel il s’agit d’un visage dont il s’agit.
À propos de ce qui est intéressant dans un image, ou d’autres images, peuvent être réduites à la pensée géométrique ci-dessus, il semble faisable de chercher même d’autres motifs. Cependant, il semble courant de placer beaucoup de tâches dans ce que l’on appelle l’ingénierie des fonctionnalités, c’est-à-dire comment décrire ce qu’est une chose pour qu’elle soit trouvée dans une image.
Dans le cas de la reconnaissance faciale démontrée ci-dessus, l’image est simplifiée à 24 × 24 pixels. Et déjà avec la quantité extrêmement limitée d’informations, il existe peu de formes géométriques capables d’identifier une face sur l’ensemble des 180 000 combinaisons imaginables. En une seule photo !
En d’autres termes, une partie essentielle de l’utilisation médicale de la vision par ordinateur dépend très probablement du fait que l’on peut trouver un retour sur investissement dans l’image pour réduire la dimensionnalité, c’est-à-dire réduire la quantité de calculs à quelque chose de réaliste et réalisable. Pour la reconnaissance faciale précédemment montrée, les modèles pré-entraînés peuvent être téléchargés à partir de la grille, mais le travail devient au lieu de déterminer à quel point ils sont bons.
À l’avenir, il y aura peut-être quelque chose de similaire à un App Store pour acheter ou embaucher ces modèles pré-entraînés pour appliquer à leurs propres données. Si ce n’est pas le cas, construire ces connaissances sera un investissement important et ce n’est pas quelque chose que beaucoup font face à eux-mêmes.
Vision médicale par ordinateur
Dans ce domaine, il y a longtemps beaucoup de travail en radiologie, nous avons donc permis d’approfondir nos recherches. Cependant, la source de données également utilisée par la radiologie, BFR (Image and Function Registry) pour stocker des informations est intéressante à des fins plus intéressantes que celles liées au diagnostic d’image.
Après un entretien avec un spécialiste du registre chez GU, il semble être possible d’appliquer la ML comme technologie dans la plupart des documents dont on a parlé. Une poursuite concevable de ce projet consiste donc à examiner quelles recherches sont déjà en cours sur les données BFR et si où y a-t-il quelque chose à apporter.
Nous avons noté que Stanford a publié de nombreuses images thoraciques librement en ligne. Cependant, comme mentionné précédemment, beaucoup de pré-travail sont nécessaires avant de commencer à traiter ces quantités d’informations à la recherche de quelque chose. Il est possible que les sources de données d’autres parties agissent sur des données de validation lorsque nous formons ML sur des données internes. Mais tout aussi, les données d’autres organisations peuvent nuire à nos modèles de ML, afin de ne pas engranger trop de biais dans nos systèmes. Par exemple, considérez le scénario selon lequel nous recevons un patient international de toute urgence et que nous aurions accès à l’ensemble des antécédents médicaux de la personne. Il serait alors bon que notre modèle de connaissances comprenne les rayons X même s’ils proviennent d’un autre fournisseur de soins de santé.
Deep Learning
Le Deep Learning (DL) est une variante spéciale du ML conçue pour renforcer la complexité du réseau neuronal. Le réseau devient ainsi au courant des détails. dans l’ensemble de données sur laquelle il est formé et peut tirer des conclusions plus avancées. Pour que cela commence à devenir à l’épreuve des piqûre, des ensembles de données plus volumineux sont nécessaires que autrement. Ici aussi, la question se pose de savoir si c’est l’image à examiner ou si c’est le signal de ce qui capture maintenant l’image qui compte.
Une description simplifiée s’adresse à ceux qui connaissent les métadonnées pour quelque chose, les informations sur les informations, les données qui décrivent ou résument d’autres données. Prenez une photo avec votre appareil photo mobile et vous enregistrerez des métadonnées avec l’image. Par exemple, la taille de l’ouverture de l’ouverture, l’heure à laquelle l’image a été prise et parfois des informations géographiques telles que la latitude et la longitude. La différence entre le signal et le contenu de l’image est déjà assez importante. Le signal peut relier le contenu de l’image à :
- Période de l’année. Par lieu et par date.
- Météo approximative. La combinaison de la lumière de l’image, de l’ouverture et de la synchronisation peut permettre de déterminer si le ciel était couvert.
- L’image relation avec d’autres images. En analysant des séries chronologiques pour plusieurs images, on peut voir si elles se trouvent au même endroit et ont ainsi une perspective complémentaire sur ce qui a été représenté. Pensez à des applications comme Google Street View.
Après tout, les images sont optimisées pour la consommation humaine. Dans le signal, on trouve des informations sur les machines perdues lorsqu’elles sont converties en visualisation bidimensionnelle.
Si vous vous concentrez un peu sur l’obtention des différents dossiers de qualité des soins, vous pouvez faire face aux interventions déjà faites dans le domaine des soins. L’un de ces dossiers est le registre des causes de décès. Ensuite, comment et à quoi nous pouvons accéder à un ou plusieurs enregistrements est un autre problème. Mais il est clair que les connaissances sont découvertes dans ces dossiers.
Les dossiers que notre chercheur du registre de GU a inspectés concernent environ 2 millions de personnes. Ils ne contiennent pas autant de points de données par individu, environ quelques centaines. Cependant, il existe d’autres initiatives qui peuvent compléter les informations contenues dans les registres de qualité par quelques milliers de points de données supplémentaires. L’une de ces sources de données est Scapis, une étude sur la prévention des maladies cardiovasculaires. Scapis à lui seul possède quelques milliers de points de données par individu.
Conclusions concernant la vision par ordinateur
Que vous mélangiez des images, des signaux, des données de registre volumineuses ou non, ces types de calculs sont si coûteux qu’il faut faire plus de travaux préliminaires que ce que nous avons l’occasion de faire au cours de cette étude préalable. Nous nous sommes donc concentrés sur la complexité des stocks et nous avons des propositions à venir.
Dans les cas où nous devons exécuter le Deep Learning, les exécutions peuvent être parallélisées sur des GPU. Nous avons reçu l’indication que nous pouvons probablement organiser des exécutions de données sur Chalmers si nécessaire pour ne pas divulguer de données au centre de données d’un géant informatique. Un centre de données sera peut-être lié à l’entreprise IA réalisée à Lindholmen à Göteborg, où la région de Västra Götalandsregion participe.
Il aurait été intéressant d’explorer l’apprentissage par transfert sur les images thoraciques de 40 Go publiées par Stanford, puis de voir s’il existe un potentiel de transfert de ce modèle ML vers un autre domaine de diagnostic. Dans ce cas, cela se ferait avec une expertise en matière de diagnostic en imagerie interne.
Dans le cas où l’on a besoin d’une grande puissance de calcul pendant un peu plus longtemps, un nombre croissant d’options semblent apparaître. Nvidia a publié fin mai 2018 une solution serveur appropriée, HGX-2, qui, pour un peu moins de quatre millions de couronnes, peut fonctionner à des milliers de trames par seconde.
« Nvidia nous indique également que les serveurs de test équipés de HGX-2 ont réussi à former des modèles avec des images à une vitesse de 15 500 images par seconde dans le test Resnet-50 standard. Cela signifie qu’un serveur HGX-2 devrait pouvoir remplacer jusqu’à 300 serveurs par des processeurs ordinaires. » — Nvidia lance un processeur lourd pour les serveurs avec l’intelligence artificielle ciblée (Techworld)
Un autre projet consisterait à explorer la possibilité de poser un diagnostic. via une application vers les mobiles. Prenez un selfie et découvrez, par exemple, sur :
- Il est temps de rester à l’ombre le reste de la journée.
- Il y a des signes d’accident vasculaire cérébral.
Un tel projet consisterait à inventorier les modèles de travail disponibles pour aider. Au cours de la dernière année, on a parlé des diagnostics qui peuvent être effectués avec une simple photo sur l’œil d’une personne, ainsi que de permettre de lire le pouls et d’autres paramètres vitaux avec un simple appareil photo mobile. Pouvons-nous tirer parti des conclusions d’autres personnes sur la région ?
Q&R éthiques
« une culture technologique fondée sur des valeurs blanches et masculines, tout en insistant sur le fait qu’elle est assez brillante pour nous tous servir. Ou, comme on l’appelle dans la Silicone Valley, la « méritocratie ». — Sara Wachter-Boettcher, Wrong Techniquement — Applications sexistes, algorithmes biaisés et autres menaces de technologie toxique
En 2016, une étude sur la technologie trouvée dans les mobiles d’Apple, Samsung, Google et Microsoft peuvent vous aider si l’utilisateur se trouve dans une situation de crise. La réponse courte est que ce n’est pas toujours le cas. Il y a beaucoup d’exemples extrêmes, comme Siri répondant « Ce n’est pas un problème » à la question « Siri, je ne sais pas quoi faire, ma fille est victime d’abus sexuels » ou que « Siri je ne sais pas quoi faire, j’ai été simplement agressée sexuellement » est répondu par « On ne peut pas tout savoir, n’est-ce pas ? »
Faut-il s’attendre à ce que la technologie vendue en tant qu’intelligente performe mieux dans des situations difficiles ?
Oui, au moins il pense que Sara Wachter-Boettcher qui, dans son livre Technical Wrong — Applications sexistes, algorithmes biaisés, et autres menaces de technologie toxique plaide parce que le concept informatique de « edge case » devrait être remplacé par « cas de stress ». Que quelque chose qui, selon les créateurs, par exemple, d’une application n’est pas rejetée à la hâte comme improbable, mais qui donne la priorité à essayer de trouver une solution à l’époque où ses utilisateurs ont besoin de notre tout au plus réfléchi. Ce livre devrait être lu par tous les blancs qui aiment la technologie. Le fait que tous les deux d’entre nous qui avons travaillé sur ce projet soient tous les deux des hommes blancs n’est pas une coïncidence si l’on veut croire le livre. L’agence de presse Reuters a qualifié le problème d’atteindre l’extérieur de la « cohorte traditionnelle de la Silicone Valley ». En dépit de nombreux efforts visant à accroître la diversité, il demeure vrai que lorsque les groupes marginalisés abandonnent plus largement l’industrie technologique pour commencer par autre chose, il est difficile d’améliorer durablement la diversité.
C’est pourquoi les questions d’éthique, de diversité et d’approche inclusive sont cruciales lorsque vous travaillez sur des machines d’enseignement qui affectent la vie des gens. Vous coupez en quelque sorte les préjugés et les distorsions en pierre et les transformez des règles invisibles, sauf si vous êtes activement vigilant.
«Ce qui fait ressortir les algorithmes, qui peuvent les examiner et le résultat peut être bon si l’entrée de l’algorithme n’est pas neutre. » — Les soins à l’égalité dans le monde des algorithmes (VGRBlog, 2016)
Nous n’avons pas besoin d’une IA générale qui menace l’existence de l’humanité pour entrer dans des difficultés éthiques. Ce n’est que par des défauts techniques que les inégalités sont confirmées et cimentées dans la société. Le fait qu’une personne nommée « Docteur » ne soit pas laissée entrer dans le vestiaire des femmes au gymnase avec son badge de membre peut être un bug dans le système, mais cela ne passe pas inaperçu pour celui qui est touché.
La chose normale, c’est d’être anormal
« La seule chose qui soit normale, c’est la diversité. » — Sara Wachter-Boettcher
Tout d’abord, il existe un problème qui définit ce qui est « normal ». Quelle est la perspicacité de ces personnes ou de ces personnes ? En psychologie, il existe un concept, WEARD, qui met le doigt sur le contexte dans lequel se trouvent les personnes influençant les algorithmes. WEARD est une abréviation descriptive de Western, éduqué, industrialisé, riche et démocratique. Ceux qui construisent et évaluent les algorithmes sont souvent très peu représentatifs de ceux qui seront affectés à long terme.
Le fait que le service d’imagerie de Google en 2015 ait classé la peau foncée comme des gorilles ou que les Asiatiques aient été informés de cesser de loucher avec leurs yeux par un automate photo sont des exemples d’algorithmes entraînés sur une base inférieure aux normes. Même Google, bien qu’il soit considéré comme ayant l’IA la plus intelligente, ces problèmes peuvent être liés au fait que la même année dans leur rapport sur la diversité indiquait que seulement un pour cent des employés étaient noirs. Probablement, les développeurs à la peau foncée n’avaient pas manqué de tester leur réseau neuronal avec des images de peau foncée.
Personas et publics Travailler avec des utilisateurs conçus est souvent regroupé en soi-disant personnages ou parfois publics. Il existe un risque imminent de commencer à se concentrer uniquement sur les caricatures des utilisateurs. Même dans les cas où les personas sont très détaillés, une très grande variété s’adapte. Prenons par exemple le prince Charles et Ozzy Osbourne. Ils a un tas de caractéristiques communes, notamment le fait d’être blanc, riche, marié, d’hommes originaires d’Angleterre. Mais l’un est des adeptes du trône dans une maison royale et l’autre a grandi dans une ville industrielle sale avec des parents sans le sou. Des nuances comme celles-ci disparaissent parfois même si vous pensez que vous travaillez centré sur l’utilisateur.
Certains qui avaient à la fois un budget important et pensaient centré sur l’utilisateur étaient l’US Air Force qui, dans les années 1950, a évalué si le poste de pilotage était conçu en fonction des dimensions corporelles des pilotes de chasse. Ils ont étudié un peu plus de 4 000 pilotes de chasse et ont pris leurs mesures physiques, y compris les épaules, les seins, la taille et les hanches. Au total, dix mesures ont été prises. Une fois que toutes les données ont été compilées, il a inspecté à quoi ressemblait la mesure corporelle moyenne du pilote par rapport à chacun des 4000 individus mesurés. Même en lisant les moyennes de /- 15 points de pourcentage, ce n’était pas un pilote qui était moyen sur les dix dimensions.
« Encore plus étonnant, Daniels a découvert que si vous ne choisissiez que trois des dix dimensions de la taille (par exemple, la circonférence du cou, la circonférence de la cuisse et la circonférence du poignet), moins de 3,5 % des pilotes seraient de taille moyenne sur les trois dimensions. Les conclusions de Daniels étaient claires et incontestables. Il n’y avait rien de tel qu’un pilote moyen. Si vous avez conçu un poste de pilotage pour s’adapter au pilote moyen, vous l’avez réellement conçu pour ne convenir à personne. » — Todd Rose, la fin de la moyenne : libérer notre potentiel en adoptant ce qui nous différencie
Ce qui restait pour l’US Air Force, c’était plutôt de concevoir le poste de pilotage pour supporter les extrêmes, les plus petits et les plus grands de chaque dimension fonctionneraient. Ce travail a permis de réaliser des sièges réglables, des pédales et des boucles sur les casques. Des choses que nous prenons aujourd’hui évidemment, mais qui ne l’étaient pas à l’époque.
Sans travail solide, on aurait pu aussi bien supposer qu’ils (seuls hommes dans les années 1950 ?) comme fait face à tous les exigences pour devenir pilote de chasse avaient beaucoup en commun.
Pour quiconque utilise l’apprentissage automatique pour identifier les divergences dans les sources de données, ces défis peuvent être évidents, mais la plupart d’entre nous doivent travailler activement à contester nos hypothèses inconscientes.
Algorithmes de révision dont on souhaite profiter
Une ambition raisonnable est de vouloir réutiliser ce que d’autres ont déjà produit, « se tenir sur les épaules de géants », ou éviter le contraire, ce dont nous, dans les milieux technologiques, nous plaignons généralement comme le syndrome « non inventé ici » lorsque les gens se méfient de tout ce qu’ils n’ont pas créé eux-mêmes à partir de zéro.
Disons donc que dans le secteur public, nous voulons profiter d’un réseau neuronal que nous pouvons louer en tant que service, ou télécharger un modèle de connaissances diffusé gratuitement sur Github, comment le faire ? Certaines questions se posent, notamment :
- Est-ce que nous avons de la transparence dans le réseau/modèle ? Si nous le louons en tant que service sur le net, il y a une forte probabilité que le réseau est un secret commercial. Ou que le fournisseur lui-même n’a pas de trace à 100% de sa « boîte noire ».
- Est-ce que nous avons nos propres compétences qui comprennent ? Il peut s’agir de compétences du développeur, de statisticiens, de mathématiciens, ainsi que de l’expertise du sujet dans le problème que l’on essaie de résoudre.
- Quelle est l’expérience et la diversité des personnes possédant des compétences ? Le risque réside dans le fait que le groupe compétent n’est pas représentatif ou possède les caractéristiques nécessaires pour détecter automatiquement les défauts bien à l’avance.
Une micro-inspection des questions susmentionnées, nous en avons déjà un exemple dans ce rapport. Le modèle de reconnaissance faciale a été téléchargé depuis Github. La première personne que nous avons essayé de détecter avait une barbe pleine, puis il est devenu difficile de savoir s’il y avait une bouche sur l’image. En donnant à l’algorithme beaucoup d’images dans un flux vidéo via la webcam n’a pas beaucoup aidé.
Disons que nous venons de tester ce modèle sur des femmes. (ce qui est courant au conseil de comté, par rapport au secteur de la technologie) et que notre solution consistait à répondre à la question : « La personne peut-elle sourire et montrer des dents ? » Nous avions alors essayé de « voir » si une bouche de gypse pendait. Cette application n’aurait pas été aussi utile pour ceux qui ont la barbe pleine.
FairML est un exemple de tentatives visant à trouver des préjugés dans l’apprentissage automatique. Il s’agit d’un cadre technique qui recherche le déséquilibre (voir les liens en annexe). Au fil du temps, il sera peut-être plus facile de tirer parti de la technologie pour examiner à la fois les sources de données, les modèles de connaissances prêts à l’emploi et les réseaux de neurones afin d’examiner s’il existe des défauts.
Les limites de la technologie
Un algorithme n’est pas étranger à une recette comme lors de la cuisson, corrigé d’une manière que la machine comprend. Les machines font comme elles sont instruites, il n’y a pas de magie, ce sur quoi nous comptons quand on les utilise. Cependant, les erreurs peuvent devenir dévastatrices et étendues si l’algorithme a rafales.
«Près d’un demi-million de femmes âgées au Royaume-Uni ont manqué des examens de mammographie en raison d’une erreur de planification causée par un algorithme informatique incorrect, plusieurs centaines de ces femmes sont peut-être décédées tôt. » — IEEE Spectrum (mai 2018)
En examinant de plus près un algorithme très probablement beaucoup plus simple qu’un réseau neuronal, on a découvert qu’un demi-million de femmes anglaises n’avaient pas été convoqués à la mammographie. Quelques centaines d’entre eux sont soupçonnés d’être morts à cause de cela. L’automatisation de quelque chose à l’aide de la technologie permet de gagner beaucoup de temps, mais les inexactitudes deviennent à une échelle différente de celle du travail effectué manuellement.
La technologie a également du mal à faire preuve d’empathie, il y a une absence de sentiment et de tact social. On le remarque occasionnellement, par exemple quand Siri a recommandé qu’un site web nazi soit le meilleur en avril 2018. source autour de l’holocauste, avec le titre de page « L’Holocauste » est un canular ! ». Même un humain pourrait recommander le même site, mais au moins l’homme aurait eu une certaine compréhension de ce que cela signifiait.
Même si les machines commencent à suivre le contexte et quels sont les extrêmes qui existent, il n’est pas certain que cela aide. Prenez la question de savoir si la terre est ronde, alors c’est peut-être idiot de servir les deux côtés comme égaux. Il favorise le plus les extrémistes, mais The Flat Earth Society encouragerait sûrement l’attention.
Résultats
En plus de cette compilation de leçons, l’étude préliminaire comporte un certain nombre de livraisons dans le domaine du développement, notamment :
- Un tas d’articles sur le blog de développement de Västra Götalandsregionens (voir annexe)
- Un prototype visuel de l’application pour l’Apple Watch
- Un prototype fonctionnel open source pour l’auto-triage sur l’Apple Watch, publié sur Github
- Notebook Jupyter avec PNL, qui classe l’histoire des patients en fonction du code de soins primaires du CIPC ainsi que des correspondances avec les textes correspondants sur 1177.se — voir le code du projet sur Github
- Exemple de code pour classer les images par rapport aux services de vision par ordinateur Azure de Microsoft — voir les fichiers Python sur Github
Examens qualitatifs
Pour compléter nos propres études avec davantage d’impressions, nous avons réalisé deux moments qualitatifs différents, un sondage mais également un atelier d’idées.
Enquête sur l’IA
L’enquête a été diffusée par l’intermédiaire du réseau social interne de VGR Yammer, ainsi que par courriels adressés à tous les membres du Département de la numérisation des soins. Le but de l’enquête et le gros titre de cette enquête était de déterminer les attentes en matière d’intelligence artificielle (IA). Nous avons eu 30 répondants.
Pour connaître ceux qui ont répondu et qui se renseignent un peu sur leur habitude de la technologie, on a d’abord posé la question : « Quelle est la taille du passeport ? connaissances numériques/techniques ? » lorsque nous étions curieux de savoir comment ceux qui ont répondu à l’enquête évalueraient leurs propres compétences. 70 % ont choisi « Très bien informé » ou « Très bien informé ». À peine 7 % étaient considérés comme « très ignorants » et les autres ont choisi « Ni ni ».
En d’autres termes, la plupart des accusés semblent se sentir plutôt en sécurité avec la technologie. D’autres choses, il est devenu quand on lui a demandé uniquement de l’IA : « Combien de connaissances avez-vous en IA, ses différentes méthodes et sur ce qu’elle est utilisée ? » Maintenant, la proportion de « très bien informés » et de « très bien informés » a chuté à 30 %, « Ni ni » n’a obtenu 40 % et 30 % ont choisi soit « Ignorant » soit « Très Ignorant ».
« Selon vous, qui devrait avoir le niveau de détail de l’IA ? » La question est intéressante étant donné que vous vous considérez être celui qui explique comment les nouvelles technologies et les innovations font du bien dans l’entreprise. Une autre option consiste à s’appuyer sur les fournisseurs et leurs expressions préférées, que nous devrions « nous concentrer sur notre « cœur de métier » et laissez les autres faire tout le reste pour nous.
Parmi les répondants, 20 % ont choisi que la région de Västra Götalandsen elle-même ait la connaissance des détails, 33 % pensaient que c’était la responsabilité de fournisseurs externes et, de façon intéressante, le reste a indiqué qu’il incombait à chacun d’avoir des connaissances détaillées. La réponse à cette question pourrait également être justifiée.
Ces justifications étaient assez consensuelles. Pour acquérir un soutien ou une expertise en IA, il faut posséder de bonnes compétences en matière de commande :
« En tant qu’utilisateurs, nous devons être en mesure de savoir comment utiliser et où nous allons. Les fournisseurs doivent être ceux qui possèdent des connaissances techniques approfondies. Mais nous défendons HURET »
« Je pense vraiment que VGR devrait avoir un certain nombre de personnes qui comprennent comment mettre en œuvre et gérer l’IA. Des détails spécifiques sur les services publics auxquels les fournisseurs externes peuvent s’occuper. »
« Si VGR veut acheter des services, VGR doit bien sûr avoir suffisamment de connaissances pour être un acheteur compétent, mais la question est de savoir si VGR doit produire des solutions d’IA à ce stade elles-mêmes. J’ai l’impression que ce serait un très grand défi pour VGR-IT. »
« Avez-vous des attentes élevées en matière d’IA au cours de la période de 3 à 5 ans, en général ? » Un troisième a choisi « Oui, absolument » et 53 % ont choisi « Oui ». Un dixième a souhaité un peu et a couru avec « Insecure » et un individu sur trente a résolument choisi « Non ». Ceux qui réagissent semblent donc s’attendre à ce que l’IA contribue d’ici quelques années. Intéressant !
« Pour VGR, quel espoir avez-vous que l’IA puisse contribuer à notre activité ? » 23 sur 30 ont choisi l’option « High Hope », 5 ont pris « Incertain » et 2 avaient « Low Hope ». Ici aussi, on pourrait justifier sa réponse par un texte libre. L’un des accusés craignait que la législation ne soit en mesure d’améliorer les opérations de l’IA.
Un autre voulait soulever le problème que dans le « business », c’est-à-dire pas le département informatique, ne travaille pas avec Agila méthodes de développement. Le défendeur a également comparé au moment où nous avons commencé à utiliser le Web dans les affaires publiques :
« Puisque le reste de la société profitera et s’habituera à l’IA, la pression exercée sur VGR fera de même. De même, toutes les organisations devaient avoir un site Web, le jour où les annuaires téléphoniques ont cessé de paraître sous forme papier. »
Beaucoup soulèvent des questions concernant l’automatisation, l’aide à la décision, la réduction de la duplication manuelle et le fait qu’il serait plus facile de savoir ce qui se passe déjà dans l’entreprise. D’autres parlent de la sécurité des patients, de meilleurs soins et de la présence d’un secrétaire médical semblable à SIRI.
Un défendeur a exprimé un certain scepticisme quant à la question de savoir si l’entreprise est même intéressée :
« La technologie est une chose en soi, mais la façon dont l’entreprise devrait se lancer sur l’existence de l’IA, je suis plus hésitant »
« Quel problème commercial aimeriez-vous voir résoudre et pourquoi ? » Nous abordons maintenant les questions restantes où un seul peut spécifier des réponses en texte libre. Il n’est pas surprenant que la technologie intelligente puisse réduire la quantité d’administration, de sorte que l’on ait plus de temps avec les patients, ou d’obtenir de l’aide pour la manipulation et l’évaluation même en dehors du secteur des soins :
« C’est peut-être bon de commencer dans le monde administratif, nous n’aurons pas à risquer des vies… par exemple, l’évaluation des subventions et des bourses d’études. Un algorithme pourrait facilement effectuer une évaluation du crédit, lire la demande, envoyer des confirmations, gérer des rappels à certains jalons du processus, etc. L’IA ne peut initialement être qu’un conseil et proposer une évaluation à laquelle un gestionnaire de cas est autorisé à dire oui ou non. Et prenez soin des réservations. Pourquoi avons-nous encore des gens qui réservent nos voyages ? 😛 »
D’autres expriment le désir de fonctions d’alarme automatisées, qu’elles puissent aider à la sursursistance de la langue où le personnel est aujourd’hui chargé d’interpréter les enfants du patient.
Une autre personne se fait soigner sur mesure :
« L’IA devrait avec l’utilisation de grands ensembles de données permet de produire des profils de risque et de calculer les interventions appropriées »
Une pluralité mentionne la possibilité de tirer des connaissances à partir de plus grandes quantités de données, ce qu’un conseil de comté devrait bien sûr disposer de suffisamment d’informations.
Un autre accusé est sur la même voie que nous, ce triage peut être heureux d’être disponible dans le coin calme de la maison :
« Donnez au public la possibilité de poser des questions liées à la santé et d’obtenir des réponses en temps réel, des traductions qui sont meilleures que Google Translate, aident les personnes âgées et malades à la maison, aident les personnes handicapées »
«Quelle solution IA vous a le plus impressionné et pourquoi ? » Cette question n’a répondu qu’à moitié. Ceux qui se sont montrés précis sur la façon dont ils ont été impressionnés ont mentionné que l’IA est meilleure que les médecins pour interpréter des feuilles de radiographie, obtenir une sous-titrage vidéo directement et que l’IA peut créer des émotions chez les humains.
Un défendeur est qu’il est démontré que les robots donnent du bien, voire mieux. la satisfaction du client et « faire un diagnostic torde un robot ne vaut pas mieux qu’un médecin ». Nous savons que la satisfaction et l’engagement envers la santé sont importants, mais la satisfaction ne compense pas un traitement inapproprié, que ce soit sur recommandation d’une machine ou d’un humain.
Quelqu’un mentionne l’ordinateur Watson d’IBM comme impressionnant, la machine qui a remporté Jeopardy aux États-Unis. Cependant, la même personne a des nuances en ce qui concerne la « connaissance absolue » qui n’est pas complètement transférable au monde médical.
En conclusion, une personne a réfléchi aux possibilités des machines de voir des modèles à la fois plus rapides et plus complexes que les humains :
« Pour voir les relations dans de grands ensembles de données afin que les données probantes puissent être trouvées plus rapidement sur différentes méthodes de traitement. »
« Dans votre journée de travail, que verriez-vous idéalement automatisé (donc vous ne le faites pas) ? » Une personne voit idéalement que toute la vie professionnelle a été automatisée, mais beaucoup ont mentionné des tâches telles que l’exploitation forestière. dans, feuille de temps, facture et autres choses pouvant être utiles par un assistant numérique. D’autres pensaient que l’automatisation devrait pouvoir trier les courriels pour qu’elle devienne gérable, répondant au téléphone, regardant dans le monde entier, compilant des brouillons, disons, rapports et rédaction de textes.
Un secrétaire médical signale des activités répétitives qui peuvent ne pas nécessiter l’attention d’un humain :
« La plupart de mes fonctions en tant que secrétaire médical sont de faire des post-vérifications, de rechercher des changements ou de saisir des informations généralisées qui, je ne pense pas, devraient être effectuées manuellement. »
On comprend alors de nombreuses tâches qui pourraient être révolutionnées et non forcées par télécopie, puis par courrier électronique, suivies de formulaires Web pour être entièrement automatisés :
« On a l’impression que nous évoluons à différentes échelles. Nous soumettons toujours des demandes papier au comité d’évaluation de l’éthique. Je ne pense pas que l’IA soit nécessaire pour que l’on puisse présenter une demande électronique au comité d’évaluation de l’éthique, mais s’il le fait, ce serait très bien. »
« Autre chose que vous voulez dire sur l’IA ? » La question finale a donné à tout le monde la possibilité d’écrire une réflexion supplémentaire facultative, nous avons peut-être manqué n’importe quelle question selon ceux qui ont répondu. Une personne pense qu’il faut proposer des cours, un webinaire et des opportunités d’inspiration dans le catalogue de cours de l’employeur.
« Il y a beaucoup de domaines qui bénéficieraient grandement de l’IA, mais pas les groupes professionnels s’assoient et ne s’arrêtent pas. L’IA doit entrer dans les soins et le soutien »
Une personne sage s’oppose un peu à ce qu’il s’agisse d’une technologie à la recherche d’un problème, au lieu de l’inverse :
« L’IA est bonne, nous allons utiliser ces possibilités… Mais ça devient un peu bizarre quand on prend l’avamp dans une technologie spécifique comme l’IA. Il serait préférable de partir des défis qui existent et de voir comment nous pouvons les résoudre. L’IA peut alors être un outil précieux. Ne pas jeter la technologie sur l’entreprise sans se concentrer sur ce qui peut être amélioré… »
La dernière réponse que nous voulons soulever concerne la fatigue technologique qui existe :
« Comme toutes les nouvelles, il faut avancer lentement et ancrer, il est important qu’il y ait un soutien pour les solutions techniques. Toute la technologie est désordonnante et nous devons ensuite avoir une fonction de support. À ce stade, nous n’avons guère de soutien sur les systèmes dont nous disposons. À la lumière de cela, l’IA se sent très loin. »
Atelier d’idées pour démêler les opportunités, les menaces et les solutions possibles
En complément de l’enquête et pour que des groupes à large représentation se rendent compte de leur point de vue sur l’IA, un atelier d’idées a été organisé. En plus de présenter le projet et de ce qui serait mis en œuvre, il y a eu trois laissez-passer de travail pour les deux groupes avec quatre participants chacun.
Parmi les participants figuraient des psychologues, des médecins, des chefs de projet possédant des compétences spéciales en IA, des responsables du développement, un chercheur dans ce domaine. leaders de l’informatique et de l’innovation.
Les premiers laissez-passer de travail étaient d’écrire sur les correctifs tout ce que vous considérez comme des opportunités avec l’IA et l’apprentissage automatique. Pour aider les groupes au démarrage, il y a eu des exemples de problèmes tels que :
- Qu’est-ce que l’AI/ML peut apporter aux soins ?
- Utilisations de l’IA et des « machines » ?
- Comment se porte ce patient à l’amiable ?
- À quoi une machine peut-elle faire face au sein de votre travail ?
Ce laissez-passer a été l’occasion d’être positif. Quelque chose de chanteur a décroché tous les correctifs dans les catégories de diagnostic, de réunion de soins, de traitement et autres.
Parmi les possibilités écrites sur des patchs, entre autres, ont été récupérées :
- Sécurité des patients grâce à un deuxième avis automatisé.
- Auto-triage.
- Automatisez la saisie dans le journal.
- Évaluation de l’impression IVA/soins aux patients hospitalisés
- Automatisez le contact et le traitement des patients.
- Égalité et soins préjugés.
La deuxième passe de travail est exactement le contraire. Il s’agit d’approfondir toutes les préoccupations, d’énumérer leurs préoccupations concernant ce qui pourrait mal tourner et les menaces. Une gestion proactive des crises, pour que vous sachiez peu quels sont les problèmes que les gens pourraient avoir, puis vous y préparer au moins.
Ici aussi, nous avions plusieurs exemples de questions pour lancer la discussion.
- Quels sont les obstacles qui existent ?
- Pour les soins ?
- Le patient ?
- Inconvénients de l’AI/ML ?
- Que signifie automatiser les gens à distance ?
Les groupes ont pris en compte les taches rouges. Pour la troisième et dernière passe de travail, ils se sont relâchés sur leurs taches rouges en essayant de trouver des solutions aux préoccupations. Dans les cas où les réponses indiquaient qui résout les difficultés, ce qui résout et comment cela se fait.
Les difficultés concernent ce qui se passe dans une IA. Est-ce une boîte noire qui ne peut pas être vérifiée ? Est-ce que nous avons confiance, et comment est-il légal ? Des questions un peu plus pratiques ont porté sur le manque de vision, de stratégie et l’on ne sait pas clairement qui est responsable de la mise en œuvre de la technologie.
Comme solutions possibles aux problèmes, on a mentionné la gestion de la formation et les opérations de base. Il souhaitait également embaucher des architectes IA et créer un centre de connaissances. Pour remédier au problème de confiance, il faut trouver une forme de transparence réalisable. Il a également été exprimé l’espoir qu’avec des algorithmes intelligents, vous pourrez utiliser les sources de données déjà existantes afin qu’elles puissent être utilisées pour l’IA.
Conclusion — que voulons-nous faire à l’avenir ?
En plus du fait que nous continuerons à explorer ML pour le reste du projet (année précédente), nous avons déjà des inquiétudes concernant des projets secondaires spécifiques que nous avons l’intention de commencer si nous trouvons le bon copains de projet.
Nous envisageons une ou plusieurs des orientations suivantes :
- Recherche dans le registre ML , ainsi que des chercheurs en ométrie de la santé à GU.
- Prêchez la réintégration . Un objectif déjà évoqué par l’unité Epsykiatry de SU. La géométrie sanitaire de GU pourrait vraisemblablement offrir aux ex-jobers.
- Transférer l’apprentissage en vision par ordinateur , par exemple, pour le diagnostic d’image avec les radiologistes.
- Vision par ordinateur : Formez vos propres classes d’objets visuels (COV) à partir de quelque chose de médical. Est-ce que nous disposons de données uniques dans le BFR ? Il peut s’écouler plusieurs mois ou plusieurs années si vous n’avez pas le bon matériel ou si vous parvenez à paralléliser à plus grande échelle.
- Apprentissage en profondeur et transfert pour étudier les visages à la recherche de diagnostics, de conseils d’autosoins et d’auto-triage dans la vie quotidienne. S’applique pour trouver une bonne source de données et suffisamment de puissance de calcul.
- NLG (Natural Language Generation) . Description des mesures et autres mesures non textuelles avec texte brut ou lisez-le. Par exemple, c’est un défi pour ceux qui voient de mauvaises données de table de lecture, ou pour ceux qui ont du mal à comprendre, un résumé descriptif ou une conclusion peut aider au lieu de devoir charger leur mémoire de travail.
- PNL pour étudier les antés/anamnèse des patients , peut-être avec des spécialisations telles que la priorité dans les soins. Nous avons déjà un contact avec un médecin à l’hôpital universitaire Sahlgrenska avec qui collaborer.
- NLP pour automatiser la création de compilations personnalisées d’informations sur les patients à partir de sources telles que 1177.se, entre autres. Ces conseils peuvent être demandés via une interface basée sur la conversation et permettent également de choisir de faire lire ou charger le matériel compilé sous forme de livre audio.
- PNL : Déterminer si les vecteurs de mots agissent comme une technologie dans un contexte de soins.
- Autres : Une compilation de réseaux neuronaux médicalement utiles en tant que service, modèles ML téléchargeables déjà formés, ainsi que des détecteurs de fonctionnalités. Des marchés crédibles sont-ils disponibles pour cela ?
Nous allons rencontrer Chalmers Innovation Office, principalement pour trouver des correspondances appropriées au sein du NLP/NLG. Reste à savoir avec quelles autres parties nous choisissons de travailler.
En plus de chercher des partenaires de projet, nous chercherons du financement en répondant aux appels d’appel appropriés.
Annexe
Tout n’est pas approprié à prendre en compte dans le rapport. Par conséquent, ici les choses du personnage liront plus de détails geek.
Glossaire
Gardez à l’esprit que certains mots du dictionnaire ont une signification différente dans d’autres contextes.
- Algorithme — une sorte de recette ou d’approche qu’une machine peut répéter maintes et maintes fois.
- Amazon Echo (Alexa) : un haut-parleur intelligent avec lequel on peut parler, poser des questions et demander à noter choses.
- Anamnes — histoire d’antécédents médicaux, un peu une interview écrite par des professionnels de la santé lors d’une rencontre avec le patient. Un appel guidé pour parvenir à une action appropriée.
- Apple Siri, SiriKit — la plateforme d’Apple pour converser avec ses gadgets. Tirer parti des serveurs Apple en arrière-plan pour comprendre ce qui est dit et l’intention de l’utilisateur.
- Application Programming Interface (API) — une façon de parler à quelque chose de technique. C’est l’entrée d’un service que vous louez en ligne pour la reconnaissance d’images, par exemple.
- Intelligence artificielle (IA) — que quelque chose d’artificiel et de création peut présenter un comportement intelligent.
- Adaptive Boosting (AdaBoost) — un méta-algorithme pour arriver à la réponse la plus probable d’une multitude d’options.
- Apprentissage par lots — que le réseau de neurones apprend de nouvelles choses furtivement, avec des paquets de nouveaux matériaux sur lesquels travailler. Comparer à apprentissage en ligne.
- Les arbres de décision — un moyen structuré de prendre des décisions. Imaginez un tronc d’arbre comme entrée et, selon les questions et réponses, certaines des branches les plus rugueuses deviennent actuelles. Plus il y a d’informations, plus on se rapproche d’une feuille. La feuille peut symboliser un diagnostic.
- Aide à la décision — pour obtenir un soutien basé sur des données pour arriver à une décision.
- Biais — avoir une distorsion dans une certaine direction. Utilisé à la fois sur les sources de données et sur les conclusions que l’on peut tirer grâce à l’apprentissage automatique. Un exemple est la recherche d’images de Google qui s’est avérée préjudiciable lors de la recherche d’adolescents noirs en les montrant dans un contexte criminel, tandis que les adolescents blancs souriaient et arboraient.
- Registre d’images et de fonctions (BFR) — registre médical unique au monde, y compris les images radiographiques et autres examens radiographiques. Opéré par la région Västra Götaland (VGR).
- Business Intelligence (BI) — concepts de collection pour travailler afin de mieux comprendre leurs propres activités. Souvent, en choisissant des données et en prenant des décisions basées sur des données au lieu de ressentir/de l’expérience intestinale.
- Classificateurs en cascade — voir Boosting adaptatif.
- Vision par ordinateur (CV) — pour permettre aux machines de voir et d’interpréter des éléments visuels tels que l’image, la vidéo, etc.
- réseau neuronal convolutionnel (CNN) Le est le plus couramment utilisé en vision par ordinateur et est un réseau neuronal qui, pour chaque couche, affine son impression d’une image, par exemple. Il s’agit donc d’une description de la façon dont la coopération est effectuée entre les couches cachées du réseau.
- Deep Learning (DL) — une variante spéciale de l’apprentissage automatique qui utilise de nombreuses couches cachées et une complexité plus grande que autrement.
- Entropie — mesure quantitative de l’ordre ou de la structuration d’une quantité d’informations.
- Détection/ingénierie des fonctionnalités : la partie ingénierie consiste à développer un moyen pour reconnaître quelque chose, comme un œil dans une image. Un « détecteur » est le résultat de l’ingénierie, donc celui qui reconnaît quelque chose de certain. La détection des fonctionnalités est l’activité même qui consiste à essayer d’identifier une ou plusieurs choses.
- Generative Adversarial Networks (GAN) — deux réseaux neuronaux qui apprennent ensemble. L’un a pour rôle d’essayer de défier l’autre. Le résultat est un réseau qui permet de séparer les faux du matériel réel et un autre réseau qui est bon pour essayer de se faire duper.
- Github — service développeur que vous pouvez trouver sur github.com, où il y a du code source, des exemples de solutions dans tous les domaines techniques possibles.
- Google Home — enceinte intelligente de Google, voir également Amazon Echo.
- Unité de traitement graphique (GPU) : processeur graphique ou carte graphique. Ils sont particulièrement adaptés à l’apprentissage automatique car ils peuvent travailler sur de nombreuses choses en même temps.
- Interface — un moyen de interagissez avec quelque chose. Les interfaces utilisateur graphiques (GUI) sont ce que vous avez sur l’écran mobile, à laquelle votre mobile va parler est une interface vocale, que le mobile vibre pour vous dire que quelque chose est une interface tactile/haptique.
- Couche cachée — est normalement une pluralité de couches dans un réseau de neurones. Ils sont appelés masqués car ils ne sont pas visibles de la même manière que les couches en entrée et en sortie. Les calques masqués sont ce que l’on fait référence lorsque l’on parle de la « boîte noire » d’une IA.
- Hypothèse — une hypothèse de la réalité, selon laquelle on croit que quelque chose se trouve d’une certaine manière. Comme cela, ce rapport pense que l’apprentissage automatique est utile pour évaluer l’état de santé des patients.
- Entrée (couche) : l’entrée est ce que vous insérez dans un réseau neuronal, tel qu’une image, la couche en entrée est la première couche à recevoir l’image avant qu’elle ne disparaisse entre les couches masquées.
- Classification internationale des soins primaires (CIPC) — l’un des nombreux codeworks proposant des codes permettant de classer diverses affections dans les soins primaires. Rend que les diagnostics n’ont pas besoin d’être écrits avec du texte libre. Si vous avez fait un test sanguin, c’est « -34 », tandis que la fièvre porte le code « A03 ».
- CIM-10 — voir Codeworks.
- code fonctionne Le — un moyen de créer une structure en utilisant des codes qui correspondent, par exemple, à un diagnostic, à un échantillon de laboratoire ou à des codes similaires. Voir Classification internationale des soins primaires pour des exemples.
- Services cognitifs, informatique cognitive — processus mental consistant à prendre en charge la connaissance et la compréhension du cœur en pensant, en expérimentant et en utilisant son esprit. Quelques fournisseurs appellent leurs services cognitifs plutôt qu’intelligents ou leur ont donné un tampon d’intelligence artificielle.
- Dossiers de qualité — données collectées par les soins pour assurer le suivi de la qualité des soins. Des exemples de dossiers de qualité incluent le registre des causes de décès, d’autres traitent des soins contre le cancer, etc.
- Quooh (Classification des mesures de soins) — les codes utilisés dans les rapports au registre des données sanitaires du Conseil social. Utilisé pour compiler des statistiques sur les actions menées par les soins de santé.
- Analyse sémantique latente (LSA) — est utilisée pour calculer la parenté entre les mots ou les concepts. Un moyen de permettre à une machine de détecter des schémas tels que, dans de nombreux cas, le médecin et le médecin semblent synonymes. Mais aussi un moyen de déterminer ce qui ne semble pas appartenir ensemble, par exemple les ongles et les abcès dans des contextes anatomiques ne sont pas très liés.
- Données liées, données ouvertes liées (LOD) — un moyen de structurer les informations à un niveau qu’elle aborde les connaissances qu’une machine peut prendre en main. Comparez la façon dont un humain peut explorer Wikipédia.
- Intelligence machine : une machine affiche des pages intelligentes ou peut apporter des informations.
- Machine Learning (ML) — qu’une machine apprend quelque chose sans pour être explicitement instruit en détail.
- Lecture par machine — qu’une machine peut prendre en charge les informations. Cela pourrait s’avérer problématique lorsqu’il faut une capacité cognitive pour réapprovisionner les lacunes ou un format de document pour afficher correctement le contenu, mais qu’il est techniquement stocké un petit trou sur le bruit. Voir également Données liées.
- Modèle, modèle de connaissances, modèle d’apprentissage automatique (modèle ML) — les connaissances regroulées tout au long du processus permettant à la machine d’apprendre. Parfois, même l’architecture du réseau neuronal est généralement incluse dans le modèle, comme dans le cas où le nombre de couches cachées, l’ordre des couches spécialisées ont, etc.
- Publics — voir Personas.
- Named Entity Recognition (NER) — technique de traitement du langage naturel permettant de travailler avec du texte, par exemple pour déterminer si un humain est mentionné dans le texte, si un diagnostic est mentionné ou le dosage de médicaments.
- Génération du langage naturel (NLG) — avec la technologie crée un texte ou quelque chose de parlé à partir d’informations. Il peut s’agir d’une compilation écrite ou orale basée sur des données collectées.
- Natural Language Processing, Natural Language Processing (NLP) — concepts généraux pour traiter le texte et la parole afin de comprendre le contenu. Voir également NER, NLTK, NLU, MfL.
- Natural Language Toolkit (NLTK) — cadre technique qui aide au travail dans la PNL.
- Compréhension du langage naturel (NLU) — pour faire comprendre à une machine le langage naturel et la parole.
- Réseau neuronal, réseau de neurones artificiels (ANN) — un réseau artificiel de neurones qui imitent un cerveau. Comprend des couches telles que la couche d’entrée, les couches masquées et la couche de sortie.
- Neurone — peut également être appelé cellule cérébrale ou cellule nerveuse.
- Apprentissage en ligne — contrairement à l’apprentissage par lots, l’apprentissage constant est en cours dans le réseau de neurones. Quand quelqu’un dit son IA en apprenant constamment à mieux apprendre qu’il s’agit d’apprendre en ligne, c’est tout.
- Les vecteurs Word — une nouvelle solution de ce que l’analyse sémantique latente tente tente de résoudre. Les vecteurs de mots ont pour but de trier les choses linguistiques comme les mots qui semblent appartenir ensemble, tels que des phrases, des proverbes, etc. Word2Vec est l’une de ces solutions libérées gratuitement par Google.
- Output (layer) : la sortie est la réponse elle-même et la couche de sortie est la couche d’un réseau neuronal où la réponse sort.
- Overfitting vs Underfitting — Le surajustement consiste à tirer des conclusions trop éloignées en se basant sur les données tirées des enseignements. Un équivalent technique des préjugés. Le sous-ajustement, c’est ne pas voir de motifs qui existent réellement. Voir également biais.
- Histoire du patient — raconter gratuitement l’état de santé du patient, contrairement à l’entretien plus structuré qui se produit à une époque de l’histoire.
- Personas — Archtypes d’utilisateurs man se tourner vers une solution. Ils ont souvent un nom et une liste de propriétés descriptives pour rappeler qui est un utilisateur final.
- Pourcentage, point de pourcentage — pourcentage représente une variation par rapport à une valeur d’origine, tandis que les points de pourcentage sont un changement d’un pourcentage. Le « pourcentage » de l’anglais est égal à pourcentage, un cent représente un centième de dollar ou euro. Exemple : si le résultat électoral d’un parti politique est en baisse de 25 % à 20 % des votes des électeurs, ils ont chuté de 20 % de leurs électeurs (cinq vingt-quarts), mais en même temps ils ont chuté de 5 points de pourcentage.
- Région d’intérêt (ROI) — une surface délimitée, par exemple, une image, le lieu où se trouve quelque chose d’intéressant ou de digne de se concentrer.
- Apprentissage par renforcement (RL) — une variante de l’apprentissage automatique dans laquelle la machine essaie d’apprendre elle-même en sachant ce qui est un résultat souhaitable (fonction dite de récompense), ainsi que ce que l’on appelle il devrait essayer d’éviter (ce qu’on appelle la fonction coût-fonction). Comparez-les à aller de l’avant à vélo sans faire de vélo.
- Deuxième avis — obtenir un deuxième avis autour de quelque chose. Comme exiger d’obtenir une nouvelle évaluation de leurs radiographies. Peut-être que cela peut être automatisé.
- Analyse des sentiments — une technique PNL permettant de lire les émotions à partir d’une masse textuelle ou d’une chose entendue.
- Auto-renfort : entrer dans une ronde de renforts positifs/négatifs sans empreintes extérieures/nouvelles. Comme si un machine learning lui-même génère des données qu’il reprend comme sa propre vision du monde.
- Snomed-CT — voir les codes.
- Apprentissage supervisé (SL) — pour former un réseau de neurones où les données que l’on utilise comme base de connaissances et contiennent des facit (appelées étiquettes). Dans le contexte médical, on a une anamnèse et le code de diagnostic selon un médecin. Voir également l’apprentissage non supervisé.
- Boîte noire — se réfère à elle dans un réseau neuronal difficile ou impossible à expliquer exactement comment il fonctionne.
- Les synaps — ce qui lie les cellules cérébrales et les neurones et leur permet de communiquer en réseau.
- Problèmes de jouets — dans l’IA, on utilise le concept de solutions à des problèmes banaux ou quelque chose dont il est difficile d’en percevoir les avantages.
- TPU (Tensor Processing Unit) — un processeur spécialisé de Google conçu pour être bon en machine learning. Voir également le GPU.
- Apprentissage par transfert (TL) — pour apporter les leçons d’un domaine et appliquer à autre chose. Par exemple, il a été démontré que les réseaux neuronaux entraînés sur les fleurs, les animaux et autres ont une certaine compréhension qui peut être utilisée dans le domaine médical en termes d’humains.
- Triage, auto-triage : le triage consiste à évaluer et à prioriser l’urgence de quelque chose. Dans les urgences, le triage est nécessaire pour dépasser les cas vraiment graves tout en obtenant le avec moins de permis d’urgence pour s’installer dans la salle d’attente. Si toutes les connaissances du triage peuvent être numérisées, on pourrait utilement triagir soi-même ou s’y rattacher.
- Protocoles de triage : les questions de contrôle, les réponses et les observations nécessaires pour effectuer un triage. Il peut s’agir de prendre un pouls, d’observer la respiration ou les ulcères, par exemple.
- Test Turing — un moyen de tester si une machine parvient à obtenir un humain avec qui il parle de croire que la machine est également un humain.
- Apprentissage non supervisé (UL) — contrairement à l’apprentissage supervisé, on ne dispose que de nombreuses données, mais il manque de facit. Cela implique de rechercher une structure dans les données, de les classer et de les regrouper à la recherche de quelque chose d’utile.
- Données de validation, données de formation : pour entraîner une machine, on divise sa source de données en au moins deux groupes différents. Les données d’entraînement sont celles qui sont utilisées pour entraîner la machine et on voit normalement la part du lion. source de données originale. Afin d’évaluer à quel point la machine est à l’épreuve des points pour prédire quelque chose, vous avez sauvegardé certaines données de validation dont la machine ne connaît rien. Lorsque vous alimentez ensuite la machine entraînée avec de nouvelles données, on peut mesurer ses performances, à quel point son « ajustement » est bon. Voir également Overfitting.
- Classes d’objets visuels (COV) : décrivez les objets visuels tels que les voitures, les personnes, les boulettes de viande, les plaies de grattage difficiles à soigner et les taches hépatiques qui doivent être traitées. En ce qui concerne le non-médical, il existe un équivalent visuel au test Turing, une compétition visant à déterminer si un humain ou une machine est le plus à l’épreuve des points dans l’identification des objets.
- Vitalis — conférence annuelle à Göteborg sur la santé, les technologies de la santé, etc.
- Classificateurs faibles — facteurs qui n’ont pas d’incidence importante sur le résultat, mais qui, ensemble, peuvent précipiter la décision de ce qu’est quelque chose. Comme ces oreilles pointues, moustaches et garrot bas c’est plus probablement un chat qu’un chien.
- WEARD — concepts en psychologie, abréviation de Western, instruit, industrialisé, riche et démocratique. Souligner le défi que ceux qui conçoivent des algorithmes n’ont pas toujours l’ambiance géante en commun avec tous leurs utilisateurs.
Matériaux d’approfondissement
Articles :
- 450 000 femmes ont manqué un dépistage du cancer du sein en raison d’un « échec de l’algorithme
- L’hiver de l’IA est en bonne voie — la critique de ceux qui survendent les progrès réalisés dans le domaine de l’IA
- Utiliser les dossiers électroniques des patients pour découvrir les corrélations de maladies et stratifier les cohortes de patients, pour voir la corrélation et l’interaction entre différents médicaments
- Stratification du patient et identification des corrélations d’événements indésirables dans l’espace de 1190 événements indésirables liés au médicament
- Les données ne sont pas la nouvelle huile (Techcrunch)
- IBM décrit les 5 attributs de l’IA utile
- Est-ce que l’IA chevauche un poney unique ? Que nous n’avons pas la rétropropagation ne nous dérangerait pas aujourd’hui au sujet de l’IA
- La crise de la réplication : difficile à recréer/reproduire les résultats au sein de l’AI/ML
- Comment démarrer vos compétences en Deep Learning à l’aide d’Apache MXNet — à propos du Deep Learning et de la PNL
- L’algorithme peut prédire si vous vivrez après une greffe cardiaque avec une précision effrayante — l’algorithme est 14 % meilleur que les connaissances actuelles
- Pourquoi l’apprentissage automatique est-il « difficile » ? Cela dépend de deux couches supplémentaires à résoudre par rapport à d’autres développements logiciels
- 300 000 fois plus de données dans les modèles d’IA — les processeurs spécialisés (GPU et TPU) vous permettent d’effectuer des calculs sur plus de données, le montant a doublé tous les 3,5 mois depuis 2012, selon l’article
- Word2vec — à propos d’une solution pour déterminer quelles relations se trouvent dans le texte, par exemple quels mots sont inclus dans des phrases, des proverbes ou d’autres types de modèles tels que le fait de suivre souvent le prénom et le nom de famille dans un texte
- Science des données — pour la prise une meilleure décision — sur les décisions axées sur les données
- Cellule grand-mère — Wikipédia — nous avons des cellules cérébrales spécialisées, y compris pour reconnaître rapidement grand-mère
- Le point de vue du Guardian sur l’IA dans le NHS : un bon serviteur, quand ce n’est pas un mauvais maître — perspective sur la collecte de données
- A Guide to Successful IA Implementations, and Why So Many Fail : comment créer un projet d’IA et apprendre de ceux qui ont échoué
- Nuances de genre — Dans quelle mesure les services d’IA IBM, Microsoft et Facebook devinent-ils le sexe d’un visage ?
- Dans quelle mesure l’IA est-elle vraiment intelligente ? Une orientation sur le thème de l’IA
- FairML : Audit des modèles prédictifs Black-Box — pouvoir inspecter les modèles ML
Livres :
- Le désir d’apprentissage automatique par Andrew Ng
- Data Science for Business : Ce que vous devez savoir sur l’exploration de données et la réflexion analytique des données par Foster Provost et Tom Fawcett :
- Notre invention finale : l’intelligence artificielle et la fin de l’humain L’ère de James Barrat
Solutions techniques :
- Apache MXNet est un environnement évolutif pour l’apprentissage afin que les données ne quittent pas l’organisation
- fitchain.io
- FairML — Framework en Python pour trouver des biais dans l’apprentissage automatique
- Bluemix d’IBM prend en charge partiellement le suédois dans la NLP — mots-clés, métadonnées et entités
Clips vidéo, démo et épisodes de pod :
- Visualisation 2D d’un réseau neuronal convolutionnel — exemple de solution de pilote pour la reconnaissance numérique
- Hello World — Machine Learning Recipes #1 — encodez votre propre machine learning en environ cinq minutes
- Simulation 3D du réseau neuronal — visualisation de l’interprétation d’images dans plusieurs couches de réseau neuronal
- Reproductibilité et philosophie des données avec Clare Gollnick dans Twiml Talk
- Les théorèmes du déjeuner sans frais de Data Skeptic
Sources de données et autres :
- SND — Service national de données suédois pour s’orienter dans les données de recherche sont disponibles
- Open API for Insurance Medical Decision Support, du Conseil social
- Watson Data Kits — données pré-lavées et structurées par IBM dans de nombreux secteurs d’activité
- COV PASCAL (classes d’objets visuels) — Exemples de reconnaissance de motifs visuels
- Le calcul haute performance (HPC) dans le cloud | Accelerated Computing — à propos de l’embauche de puissance de calcul en tant que service
Sous-rapports de projets dans le blog de développement
Sous-rapports dans l’ordre chronologique du blog de développement.
- Les projets d’IA au démarrage (inventaire des services productifiés), nous avons commencé par tester ce que proposent les fournisseurs
- IA : traitement du langage naturel renforcé par l’art noir — à propos de la PNL
- Projet IA : prototype d’application Smartwatch — exemple de démonstrateur de solution finale
- L’architecture d’information du projet IA — à propos de la source de données que nous avons inspectée par anamnèse et Codes CIPC avec diagnostics
- Converser avec des machines — à quel point ces machines comprendent-elles ce qu’elles disent ?
- GAN forme la compréhension d’une machine en se duant lui-même, en laissant une machine s’enseigner elle-même
- Apprentissage profond à l’aide à la décision pour classer les signes d’AVC ? — classification d’une expression faciale
- L’IA et la vision par ordinateur pour mieux se préparer au RGDP — à propos de la classification des objets
- Atelier d’idées sur les opportunités, les difficultés et les solutions — Atelier où différentes personnes actives dans le domaine des soins ont contribué
Merci à
Ceux qui ont relu ou contribué des conseils sur le contenu. Merci tout particulièrement à :
- Agneta Grangård
- Kerstin Hinz
- Almira Thunström
- Kristian Norling
- Stuart Filshie
- Martin Adiels
Citations sources
- fr.wikipedia.org/wiki/Artificiell_Intelligence
- fr.wikipedia.org/wiki/Machine Learning
- fr.wikipedia.org/wiki/Histoire médicale
- fr.wikipedia.org/wiki/Natural-Language_processing
- fr.wikipedia.org/wiki/Named-Entity_Recognition
- fr.wikipedia.org/wiki/International_Classification_of_Primary_Care
- fr.wikipedia.org/wiki/snomed_ct
- fr.wikipedia.org/wiki/ICD-10
- www.socialstyrelsen sen.se/classiingochcoder/atgardskoderkva
- fr.wikipedia.org/wiki/Natural_language_toolkit
- fr.wikipedia.org/wiki/Deep_Learning
- fr.wikipedia.org/wiki/Linked_Data
- api.socialstyrelsen sen.se/fmb/documentation/psi/swagger-ui.html
- www.dyslexiforeningen.se/what-ar-dyslexi/
- fr.wikipedia.org/wiki/feature_detection_ (vision_ordinateur)
- a.wikipedia.org/wiki/Réseau Neural_Convolutional_Neural
- fr.wikipedia.org/wiki/Triage
- fr.wikipedia.org/wiki/Decision_Tree
- a.wikipedia.org/wiki/faible_ai
- computersweden.idg.se/2.2683/1.698148/it-copare-ai
- a.wikipedia.org/wiki/Turing_test
- fr.wikipedia.org/wiki/Business_Intelligence
- a.oxforddictionaries.com/définition/intelligence
- fr.wikipedia.org/wiki/how_to_lie_with_statistics
- a.wikipedia.org/wiki/Réseau neural_artificiel
- www.scientificamerican.com/article/une-face-une-neuron/
- fr.wikipedia.org/wiki/Supervised_Learning
- a.wikipedia.org/wiki/labeled_data
- fr.wikipedia.org/wiki/unsupervised_learning
- fr.wikipedia.org/wiki/Reinforcement_Learning
- fr.wikipedia.org/wiki/Transfer_Learning
- fr.wikipedia.org/wiki/Kullback—Leibler_Divergence
- a.wikipedia.org/wiki/Diversity_Index
- fr.wikipedia.org/wiki/online_machine_learning
- a.wikipedia.org/wiki/sentiment_analysis
- www.chalmers.se/fr/institutions/cse/calendarium/pages/thesis-defence-olof-mogren.aspx
- fr.wikipedia.org/wiki/adaboost
- a.wikipedia.org/wiki/Cascading_classificateurs
- a.wikipedia.org/wiki/latent_semantic_analysis
- a.wikipedia.org/wiki/latent_semantic_analysis #Applications
- developer.infermedica.com/docs/nlp
- www.gu.se/reuniversity/personal/ ? LanguageId=100000&disabledirect=true&returnurl=http://www.gu.se/English /ABOUT_The_University/STAFF/%3 FLanguageId= 100001% 26 UserID=XRAWAR&UserId=XRAWAR
- aiweirdness.com/post/171451900302/do-neural-nets-rêver-de-mouton électrique
- twitter.com/picdescbot
- fr.wikipedia.org/wiki/Boosting_ (apprentissage machine) #Boosting_algorithms
- fr.wikipedia.org/wiki/Feature_Engineering
- scapis.se
- techworld.idg.se/2.2524/1.703287/nvidia-hgx2
- well.blogs.nytimes.com/2016/03/14/hey-siri-can-i-rely-on-in-a-crisse-pas-toujours-a-study-finds/
- vgrblogg.se/utveckling/2016/09/09/jamlik-vard-i-algoritmernas-varld/
- RationalWiki.org/wiki/bizarre
- spectrum.ieee.org/riskfactor/computing/it/450000-femme-manque-cancer-cancer-dépistage du cancer du sein au Royaume-Uni en raison d’une défaillance de l’algorithme
- theflatearthsociety.org
- vgrblogg.se/utveckling/2018/03/21/prototyp-pa-app-pour-smartklocka/
- github.com/Vastra-Gotalandsregionen/Guide-santé-pour-montre Apple
- github.com/Marcusosterberg/Triage-at-Home/Blog/Master/Triage-at-Home.iPYNB
- github.com/marcusosterberg/triage à domicile
- fr.wikipedia.org/wiki/Generation_Natural_Language_Generation